1. Introduction
Frequency analysis of extreme rainfall data (defined as yearly maxima of a certain duration) is a common application in hydrologic engineering. It should be applied to recorded series that follow the characteristics of independency, stationarity and homogeneity [
1]. Inhomogeneities in station data records can be due to observational routines (station relocations or changes in measuring techniques) and in that case, statistical methods and metadata information are effective for identifying these [
2]. However, some shifts in climate dynamics are a consequence of human activities [
3,
4,
5], or are related to El-Niño Southern Oscillation (ENSO) events such as those that occurred in 1976–77 [
6], or to volcanic eruptions and changes in atmospheric composition and circulation [
7].
Regardless of the reason, it is important to interpret past variability and recognize the shifts in climatic data in order to make adequate future projections. Therefore, it is crucial to investigate the effects of climate change on hydrologic time series, and especially on extreme rainfall data in order to accurately estimate or even update the intensity-duration-frequency (IDF) curves in a certain place [
8]. The IDF curves are important tools for hydrologic and hydraulic design, which nowadays faces the problems of increased urbanization and population and of climate change [
9], among others.
Trends in hourly, monthly, seasonal or annual rainfall series have been studied in several works with different results [
10,
11,
12,
13,
14,
15,
16,
17].
Numerous statistical methods such as the standard normal homogeneity (SNH) test, Buishand test, Pettitt test or Sequential Mann–Kendall test, among others, can be applied to evaluate the homogeneity of climate time series and have been widely used [
13,
18,
19]. Some of the shifts detected under these classical tests turn out to be the regular behavior of time series under the scaling assumption [
20,
21]. Therefore, authors such as [
22] recommend the consideration of scaling behavior of annual maximum rainfall when analyzing the trends in a time series, especially considering that the scaling hypothesis can increase the probability of rejection of correct null hypothesis [
23]. Thus, accounting for scaling may help to avoid contradictions in trend analysis studies [
23].
Authors such as [
24] or [
25] have analyzed changes in temporal data series during scale invariance, considering that several works have demonstrated the multifractal properties of meteorological systems [
26,
27,
28]. Those systems exhibit the same properties for different measuring scales, thus certain behavioral information can be transferred from one scale to another, which is very useful for modeling purposes.
Sometimes, different results for the year when a shift or break point is detected in a data series are obtained by different statistical homogeneity tests, and metadata or other local and climate information cannot help to determine whether a break point really exists or not. In this work, we propose a novel use of the scale invariance properties of data sets as a useful tool to confirm whether inhomogeneities previously found in extreme rainfall data series are real or not. Moreover, the methodology can also be used to confirm the existence of a shift when only one or a few statistical tests have detected it. If a break point exists in an extreme rainfall series, the two data series derived by splitting the whole one before and after that break point should have different characteristics and can be considered as different. Therefore, the length decreases and can influence rainfall data estimation when applying frequency analysis to the two data series; this element is of great importance, especially for low return period quantile estimation, and so for IDF estimation.
For these purposes, extreme annual 24-h rainfall data from eight rain gauge stations with sufficiently long series were selected in the Umbria region (Central Italy). Six statistical homogeneity tests were applied to the selected extreme rainfall series in order to highlight inhomegeneities. The multifractal properties of the data series were then used to check the existence or not of break points detected by one or a few or all tests.
4. Discussion
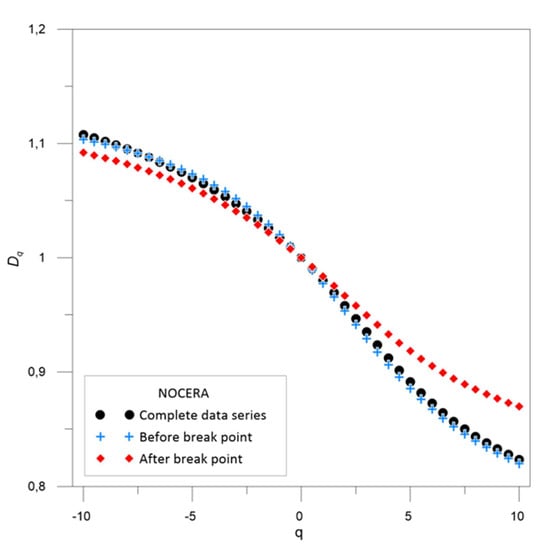
The same information can be analyzed by focusing on the similarities and differences between the fractal dimension values for complete data series and the series before and after the break points. For the Nocera Umbra station, the values obtained for the data set before the break point are similar to those obtained for the complete data set. More differences appear for the data set after the inhomogeneity. According to (D0-D1), more uniform data are found before the break point than after it. Moreover, the former data set is also more predictable than the latter, according to the (D0-D2) values.
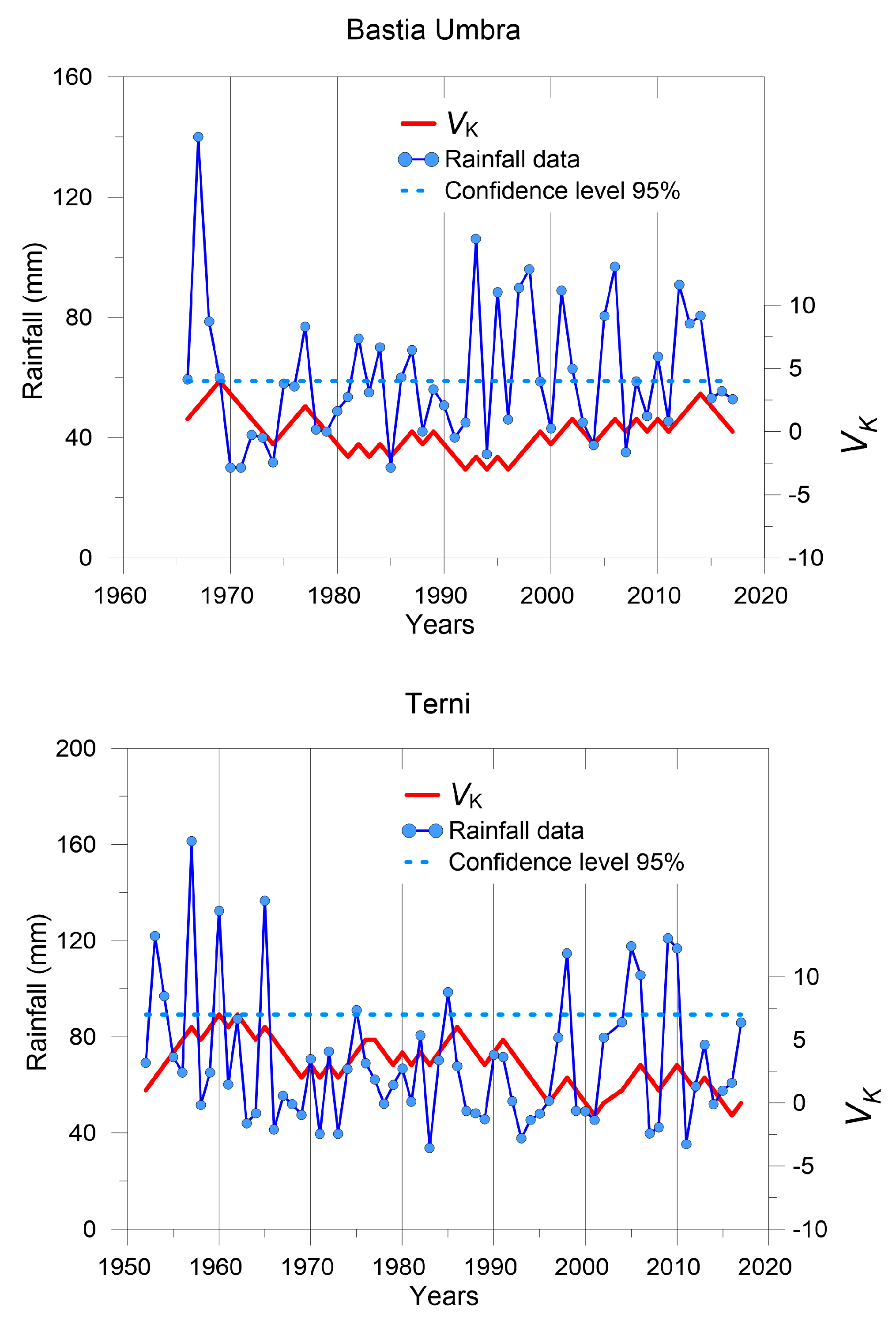
The similarities found in Nocera Umbra between the complete and one of the split data sets are also found for the Terni station, where the break point year detected is 1957. Almost equal values of D1, D2, (D0-D1) and (D0-D2) are found, showing similar uniformity and degree of predictability in the data sets.
Different values are obtained for the Petrelle data sets, with the complete data series being less uniform than the one before the break point according to the (D0-D1) values, and more predictable than the one after the break point according to the (D0-D2) values.
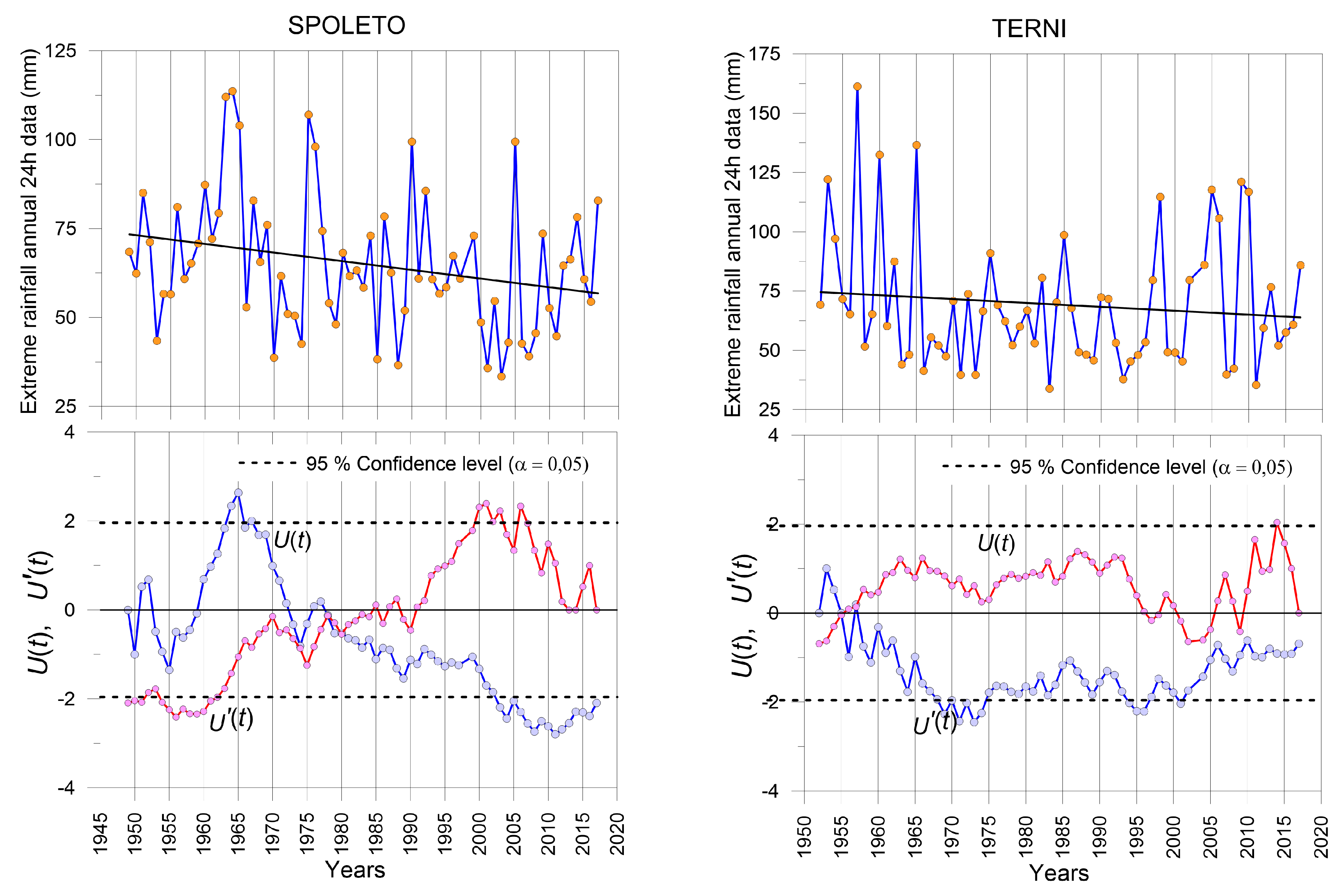
Similar values for the fractal dimension values D1, D2, and their differences with D0, are found for the complete data set of Spoleto, and those obtained with the extreme rainfall data set after 1980. Completely different values are found for both data series obtained before and after the break point in 1969, and those obtained for the complete data set.
For the Nocera Umbra station, the GFD function Dq for the complete data series is almost coincident with the one obtained for the rainfall data series before the break point. Different values were obtained for the rainfall data series after the break point. The similarity in the behavior of the complete data series and the one before the potential break point means that no real break point exists since the addition of the data after it does not change the general pattern.
The Rénji spectra obtained for the Petrelle station data series are different. In this case, the three data series should be considered as different and thus the break point is real.
No similarities arise between the data series before or after the break points with respect to the complete data series at Spoleto station if all the Dq values are considered. Nevertheless, for negative q values, similar Dq functions are obtained for the data sets before and after the break points in 1969 and 1980. These similitudes are maintained for positive q values for Dq functions of data sets before both break points. Nevertheless, Dq functions are different for positive q values for data sets after the break points, with the one after the inhomogeneity at 1980 being the closest to the Dq function for the complete data series. This behavior means that the break point took place in 1969.
For the Terni station, similar trends of Dq function are found for the complete data series and those before and after the break point year of 1957, respectively. For the former series, similar values are found for q positive values whereas for the latter the similarities arise for negative q values. Different Dq functions are obtained for those series derived from the break point in1962. This behavior implies that the inhomogeneity is placed at 1962 in the Terni extreme rainfall data series.
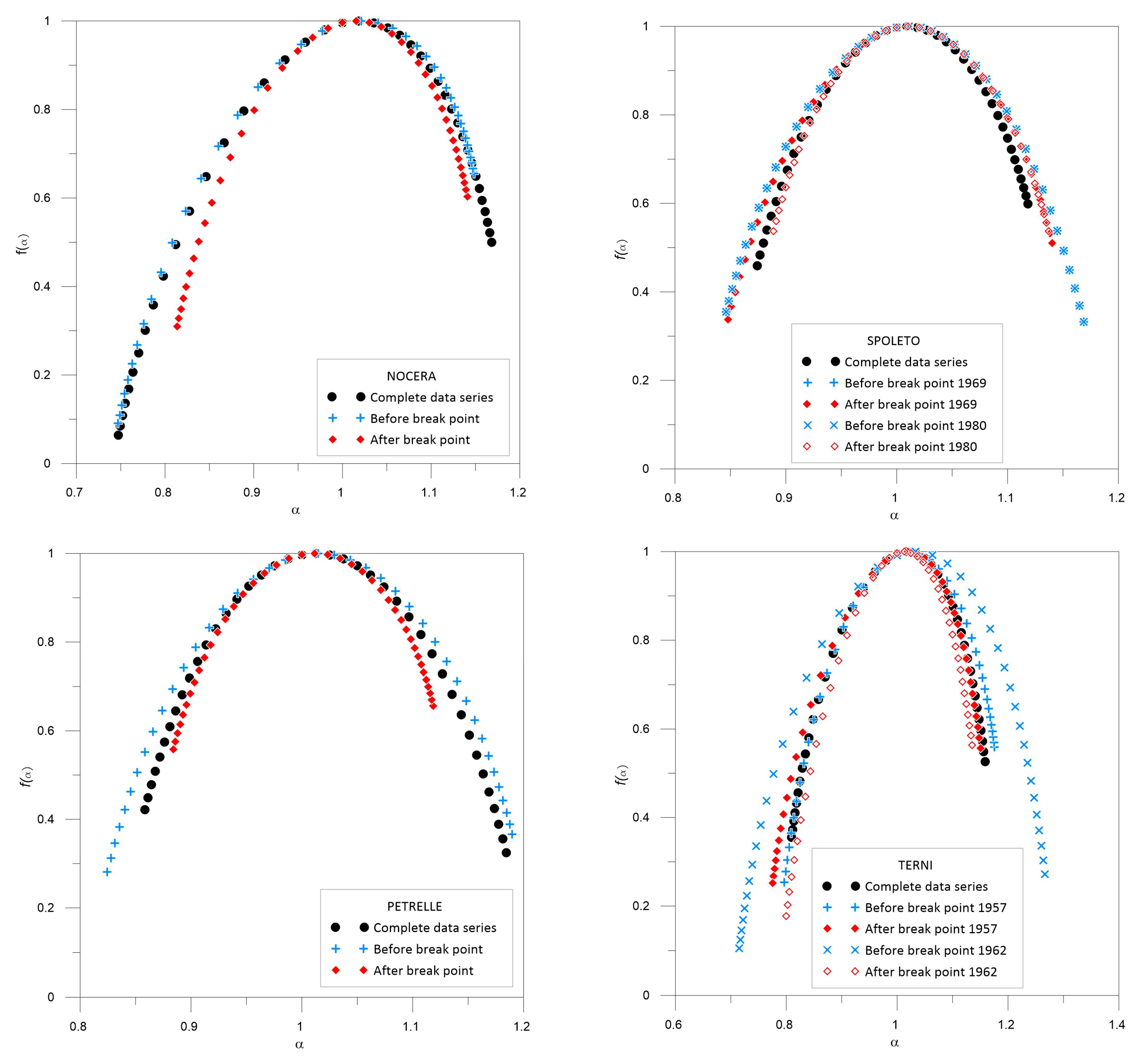
Regarding the shape of the multifractal spectra, similar f(α) are obtained for the Nocera Umbra complete data set and for the one before the break point year. Even though left-side skewed multifractal spectra are found for all the data series, the one for the data set after the break point differs from those previously mentioned.
Different multifractal spectra are also obtained for the Petrelle data sets, where not even the symmetry is similar; the complete data set spectrum is slightly right-skewed, whereas those obtained before and after the break point are skewed in the opposite direction.
Multifractal spectra before the break points appear similar at Spoleto, where the one for the complete data set also differs from those obtained before and after the break points, showing some similarities only for the left side of f(α) after the inhomogeneity in 1980.
Similarities in the multifractal spectra arise for the Terni station for both the complete data set and those before and after the break point in 1957, whereas different results are found for f(α) before and after the break point in 1962 and the whole rainfall data set.
For Nocera Umbra station, the complete extreme rainfall data series shows a negative value for the asymmetry parameter, which means that extreme events are important in the data series, and also there is a high complexity according to the value of parameter w. Even though the asymmetry parameter values are also negative for data sets before and after the break point, the last data series seems to be less influenced by extreme events than the previous one (or even than the complete series). The richness of the process is also lower for the data set after the break point than for both complete and before break point data sets. Almost similar values for all the parameters (αmin, αmax, as and w) were obtained when analyzing both the complete data set and the one before the break point.
For the Petrelle station, different values are obtained for all the parameters and data sets. The influence of extreme events is present in both data sets before and after the break point according to the negative value of the asymmetry parameter (as), whereas the complete data series shows a greater influence of less extreme events, with a positive value of as. The width of the spectra (w) is also different with a loss of richness (lower multifractality) in the complete data set compared to the one before the break point, maybe due to the influence of the data after the break point, where the richness has the lowest value.
For the Terni station, all the spectra exhibit negative values for the asymmetry parameter (as), which implies the dominance of extreme events in all the data series. The values closer to the αmin and αmax parameters are found for the complete data series and for the series before and after 1957, and thus a similar influence by extreme and smooth events can be expected for all the series. Similar complex processes are found according to the values of w. This behavior is not present for data series before and after the break point of 1962, where a loss of multifractality is found after the break point compared to the data series before it. This last data series also shows the strong influence of extreme events according to both the values of as and αmin.
The multifractal spectrum for the Spoleto complete data series shows a negative value for the asymmetry parameter, which is influenced by the presence of extreme events in the data set. The shape changes to a positive value of the asymmetry parameter for the data sets before the break points. The most similar values of all the parameters are found for the complete data set and the one after the break point of 1980.
Authors such us [
25] used the variability in the values of α
0 and w from the multifractal spectrum to assess changes in climate data series. For all the data sets studied in this work, the values of α
0 are always equal to 1 and thus no possible changes can be explained based on these values. Nevertheless, there are differences in the values obtained for the parameter that describes the degree of multifractality of the data series, w. Thus, the differences in the values of this multifractal parameter will be of great importance in deciding if a break point can really be identified in a data series.
According to all the results described above, it can be stated that no inhomogeneity exists in the Nocera extreme annual rainfall data series, whereas the break point detected in the Petrelle data set by the statistical test can be confirmed. For the Spoleto station the behavior is not as clear as in the previous stations if all the parameters are considered, but the closest similarity between complete and split data series is found in 1980, specially for the width of the multifractal spectrum (w) and the fractal dimensions D1 and D2. Thus, the most important inhomogeneity is the one detected by the statistical tests in 1969. For the Terni station, the greatest differences in multifractal properties are found between the complete data series and those obtained considering the inhomogeneity in 1962, especially for the value of w, D1 and D2. Therefore, no break point should be considered in 1957.
5. Conclusions
The multifractal character of rainfall data has been widely studied for extreme annual data of different durations and it is useful when dealing with rainfall predictive modeling or IDF estimation. Thus, the possibility of confirming the existence of a break point previously detected by statistical methods, based on the multifractal behavior of rainfall can help to enhance the results of methods and models that use rainfall as a direct or indirect input, especially, those that depend on the length of the rainfall data series.
The results of this work show that the multifractal characterization of extreme rainfall annual data series can be a suitable tool to decide whether or not an inhomogeneity exists in the data set, especially when there is no agreement in the results from statistical tests. Parametric and non-parametric statistical tests commonly applied to detect shifts in time data series were used to check if any break points were present in extreme annual 24-h rainfall data series in the Umbria region (Italy). For some of the stations considered, no inhomogeneities were found with the statistical tests.
For those stations where only one of the tests detected a break point, or where different years for the break points were identified by the different tests, the maintenance of multifractal parameters’ values was used as the criterion to reject the potential break point. Because multifractal analysis results are sensitive to climate shifts if the spectra parameters of time series divided into subsets differ, the values of the heterogeneity fractal dimension D1, the correlation fractal dimension D2, and the complexity of the data set given by w provide the bases for the decision criteria. If the complete data series maintained the values of D1, D2 or w with respect to any of the split series before or after the break point, it was considered that no inhomogeneity existed. The multifractal behavior of the split series was also found in the complete series. On the contrary, if the values of the multifractal parameters were different among the data series, the break point under consideration was accepted.
According to the results obtained in this work, the multifractal behavior of extreme rainfall data can be considered as an indicator of the changes in the dynamics of the atmospheric processes before and after observed shifts. This is of great importance in models based on extreme rainfall frequency analysis where the existence of a break point in a data series changes the length of it and can influence the estimated values. To make it easier for practitioners and engineers, a software that combine homogeneity tests and multifractal algorithms is being developed.

 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}