GIS Based Hybrid Computational Approaches for Flash Flood Susceptibility Assessment

 ,
, 
 ,
,  , , ,
, , ,
Abstract
:1. Introduction
2. Materials and Methods
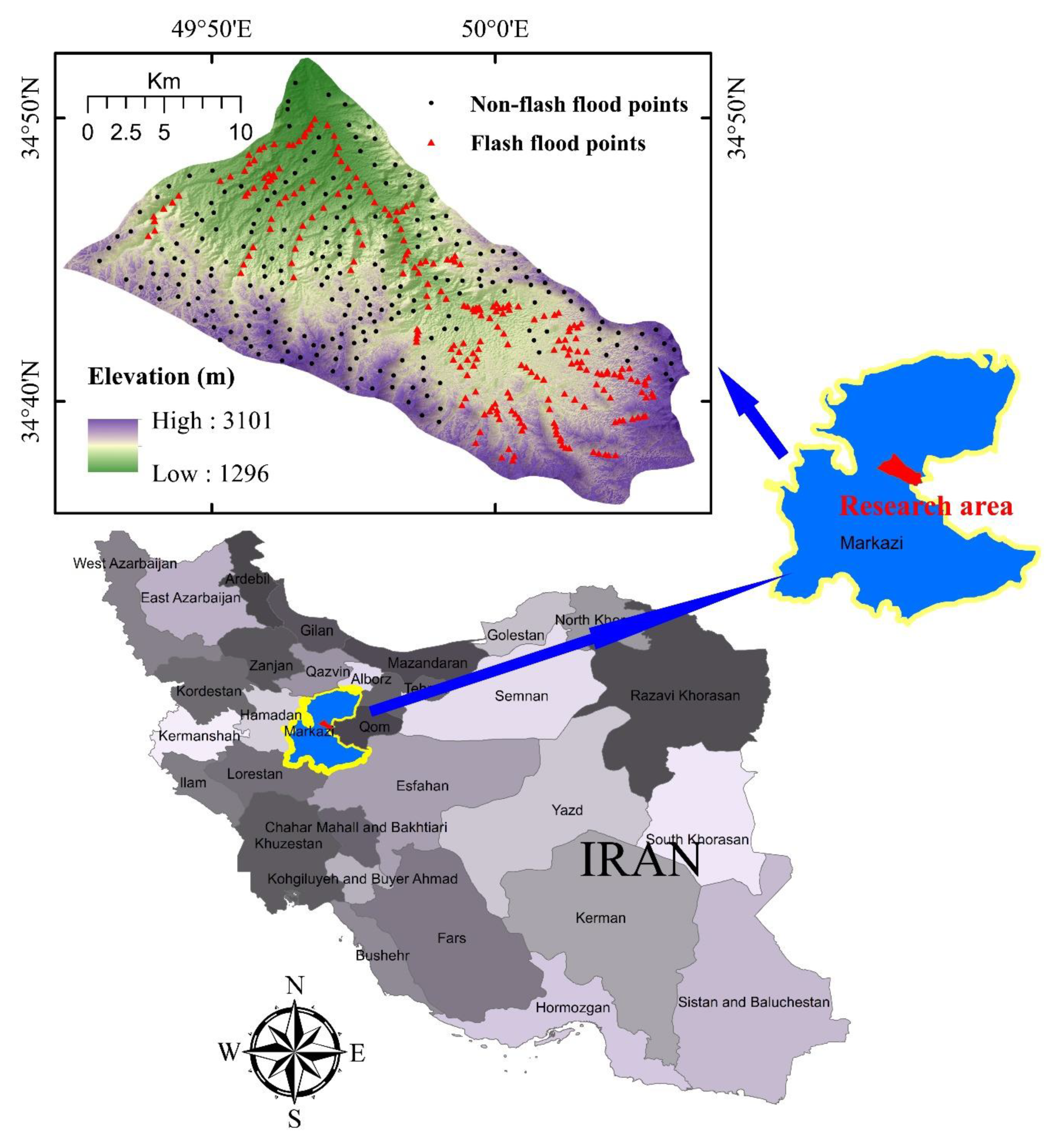
Description of the Research Area
3. Data Collection and Preparation
3.1. Flash Flood Inventory
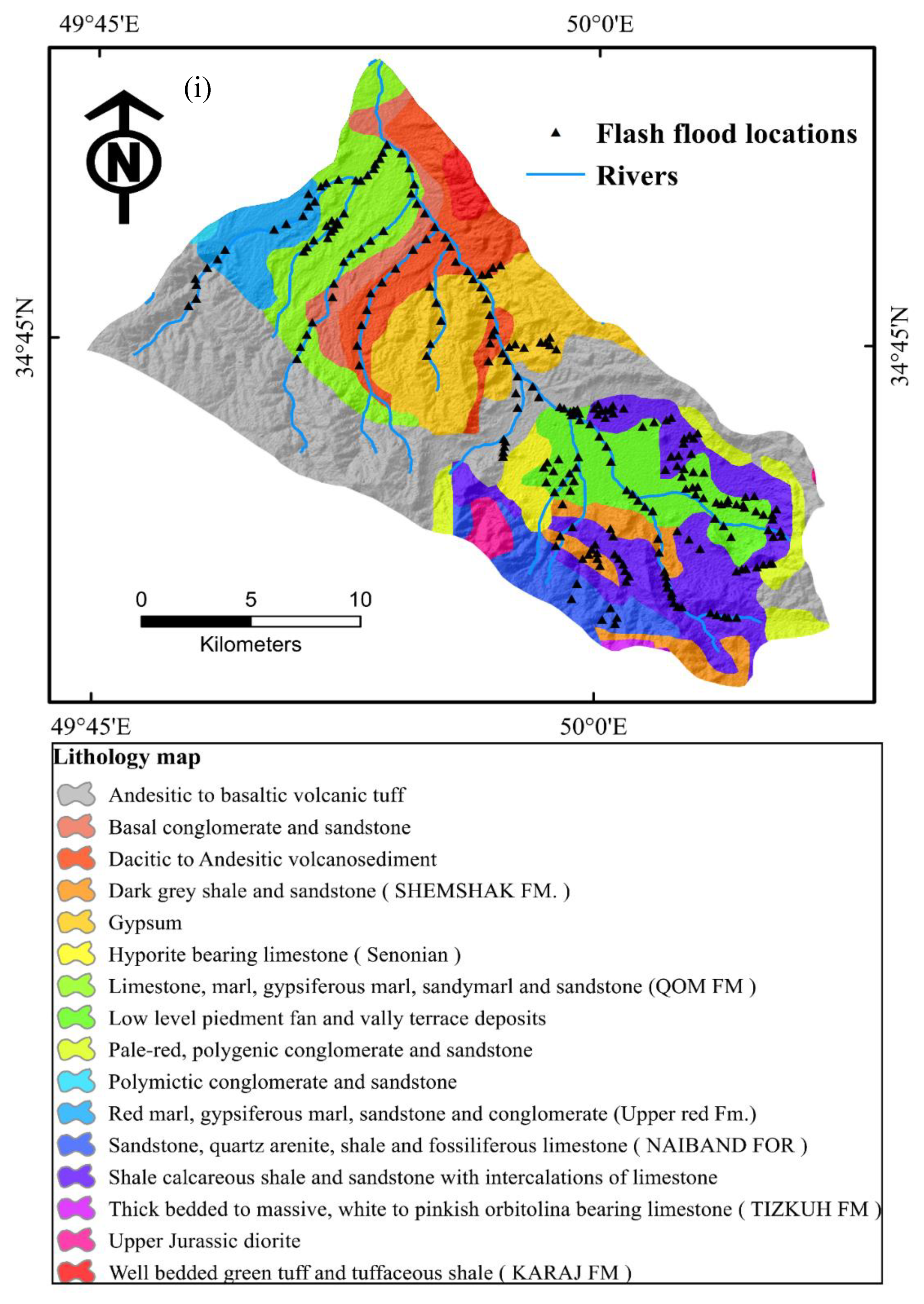
3.2. Flash Flood Conditioning Factors
4. Methods Used
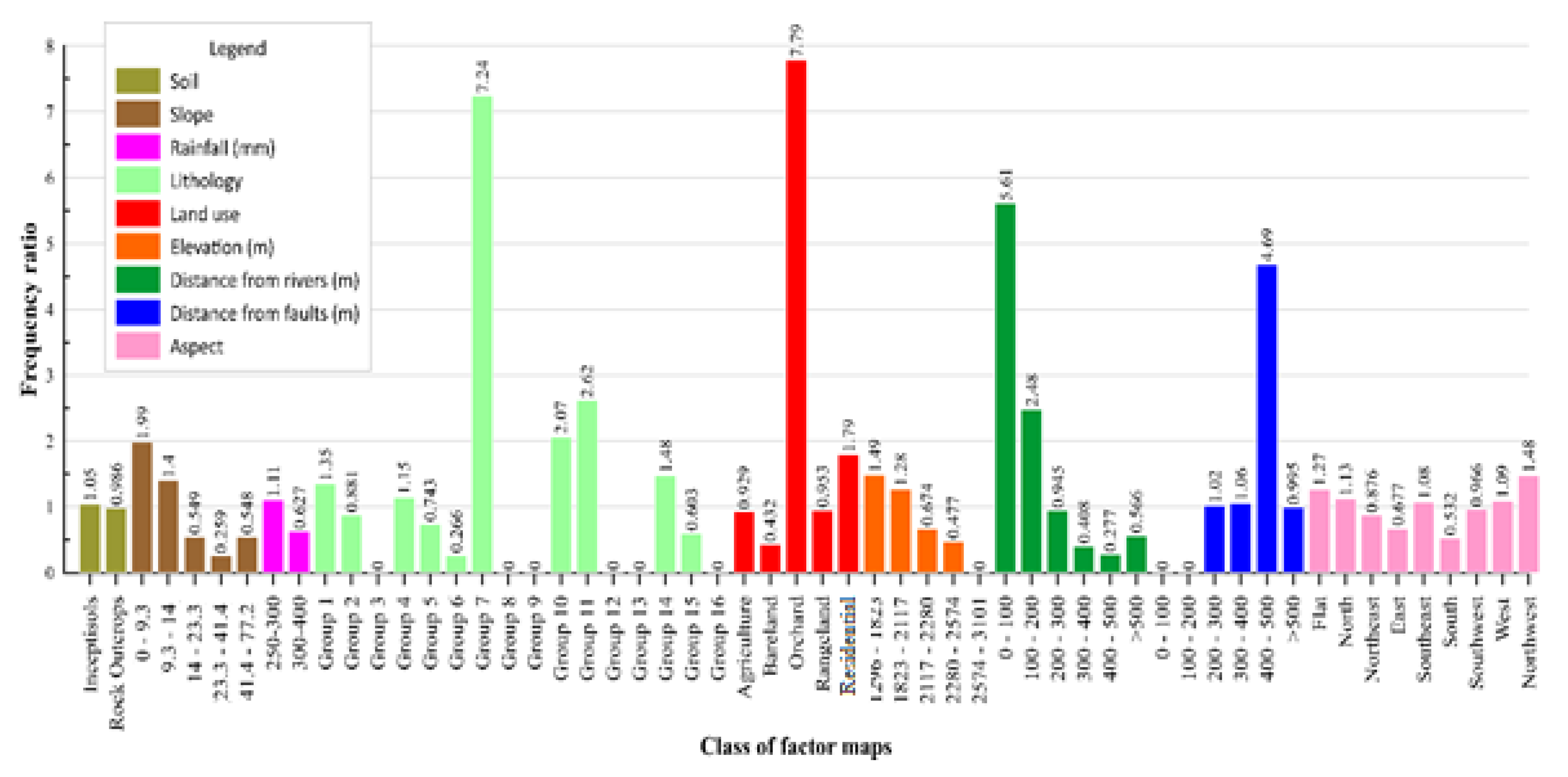
4.1. Frequency Ratio
4.2. Correlation Based Feature Selection
4.3. AdaBoostM1
4.4. Bagging
4.5. Dagging
4.6. MultiBoostAB
4.7. Credal Decision Tree
4.8. Validation of the Models
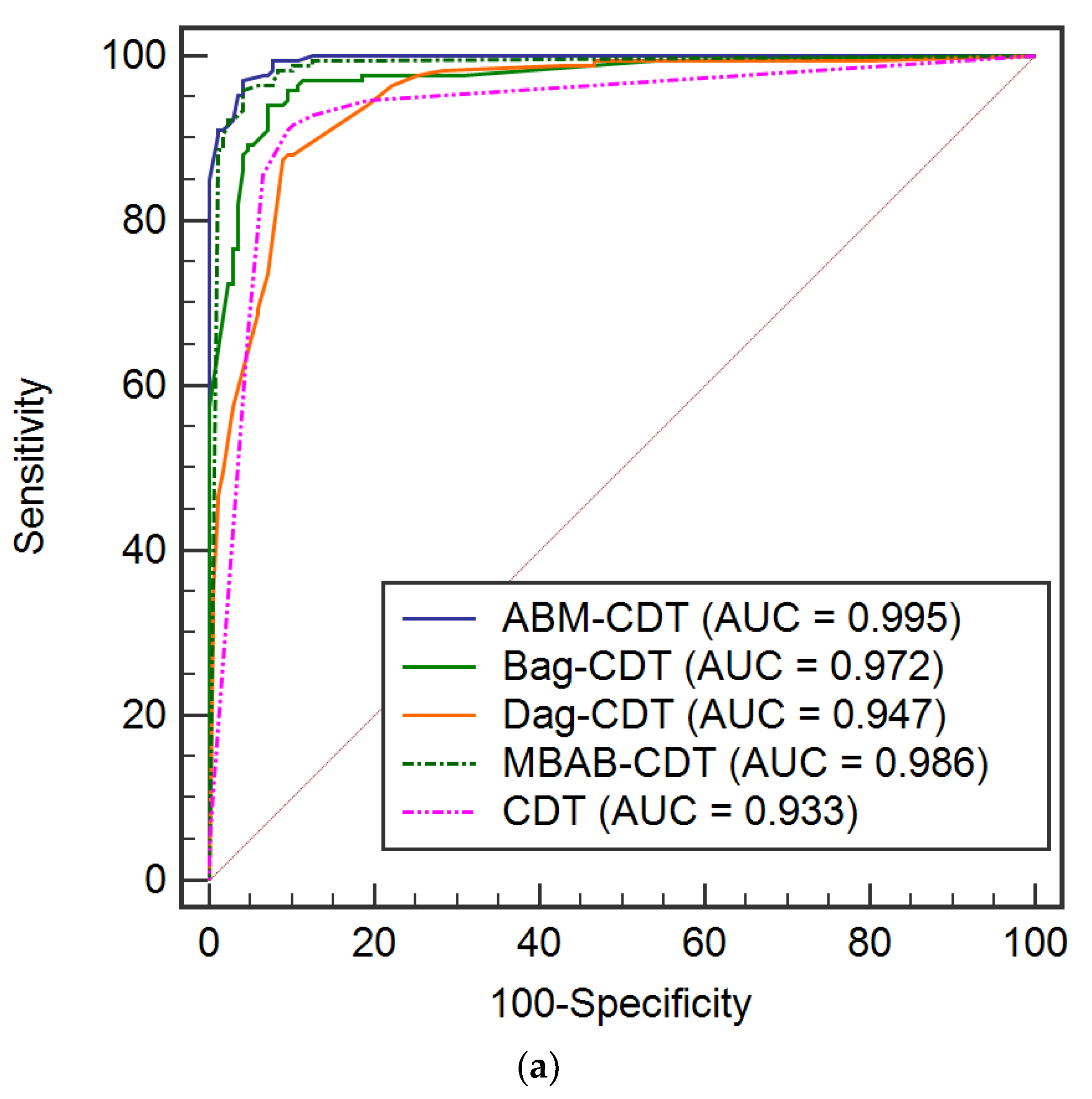
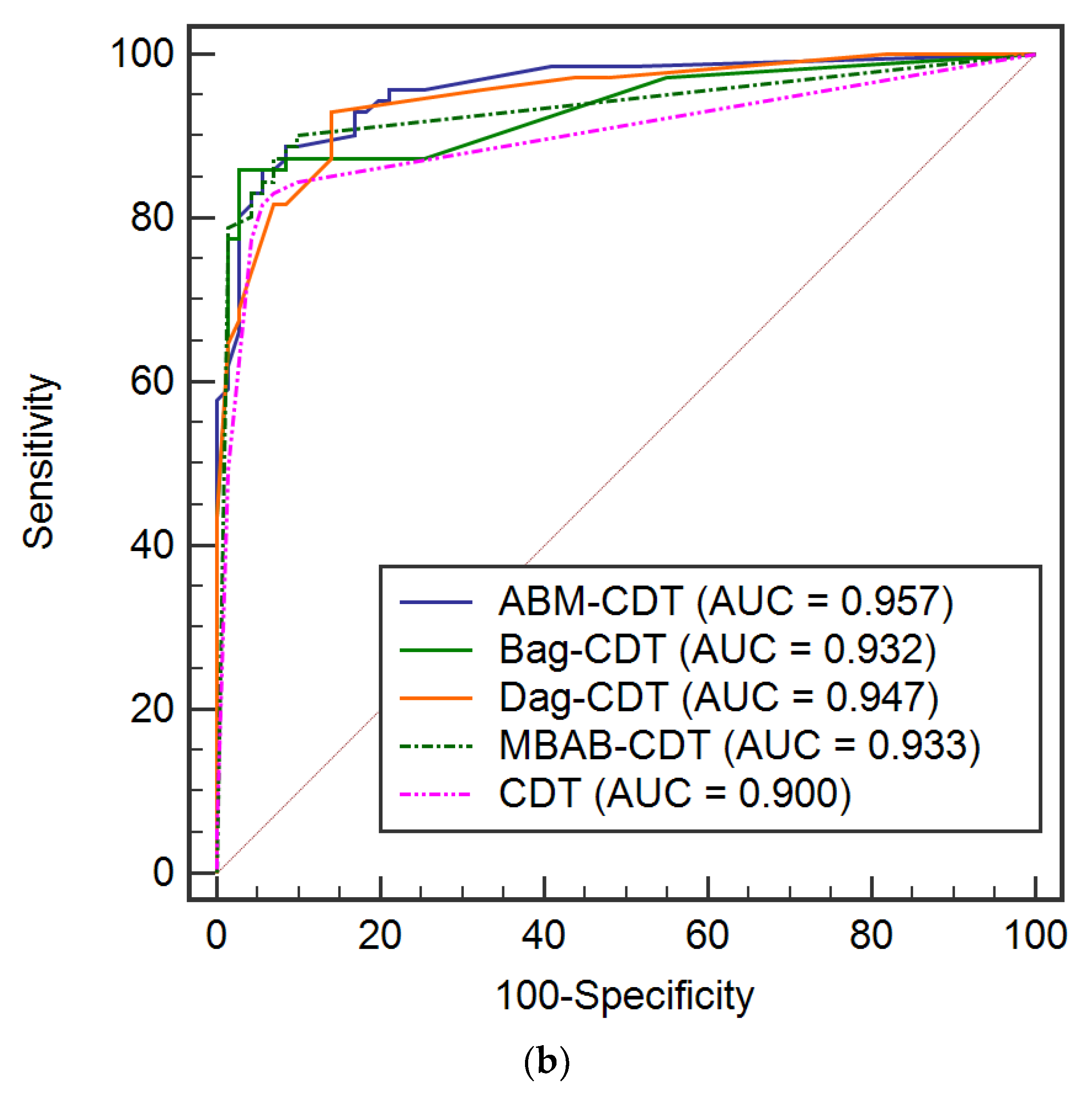
4.8.1. Receiver Operating Characteristic (ROC) Curve
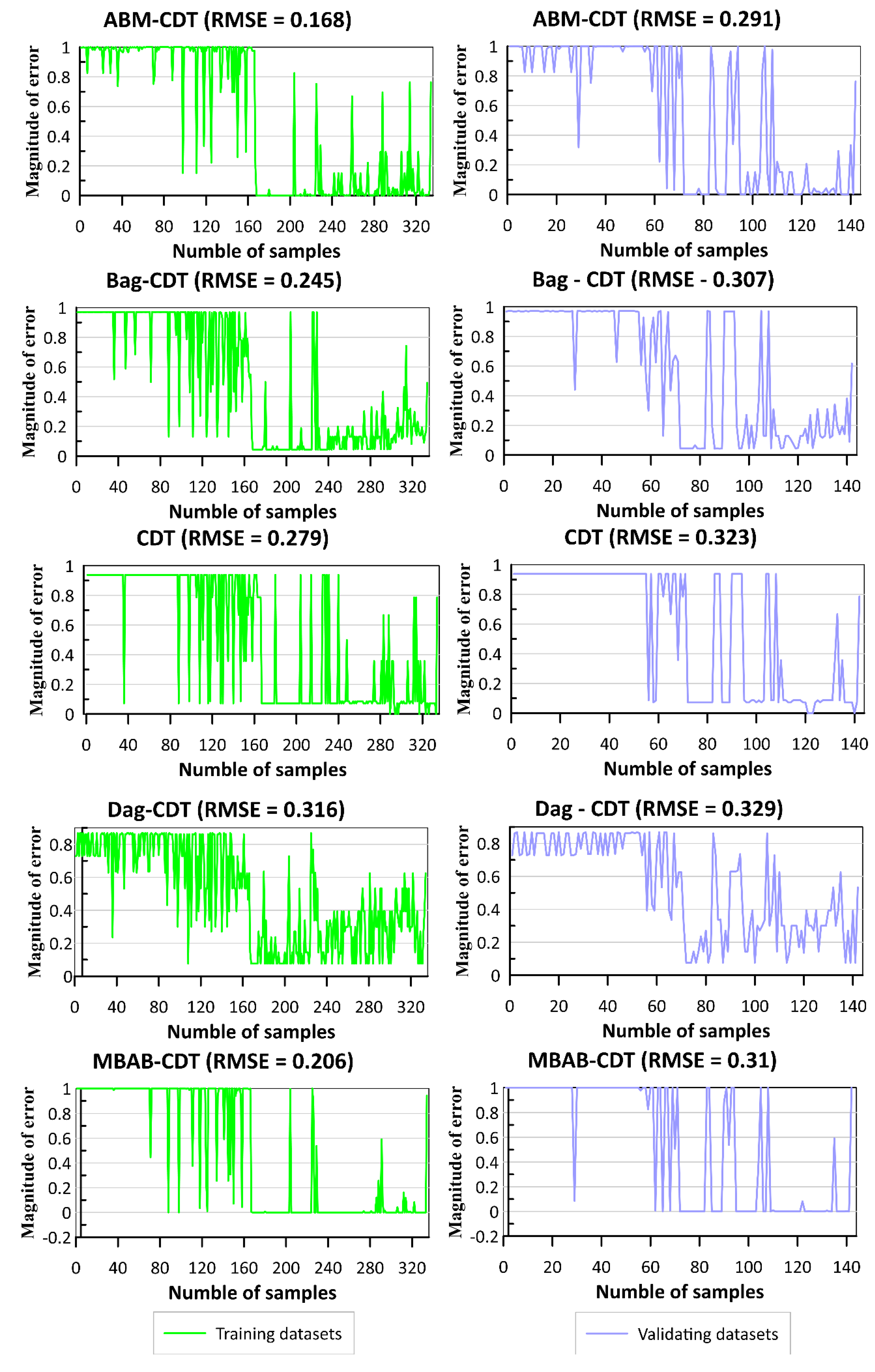
4.8.2. Statistical Measures
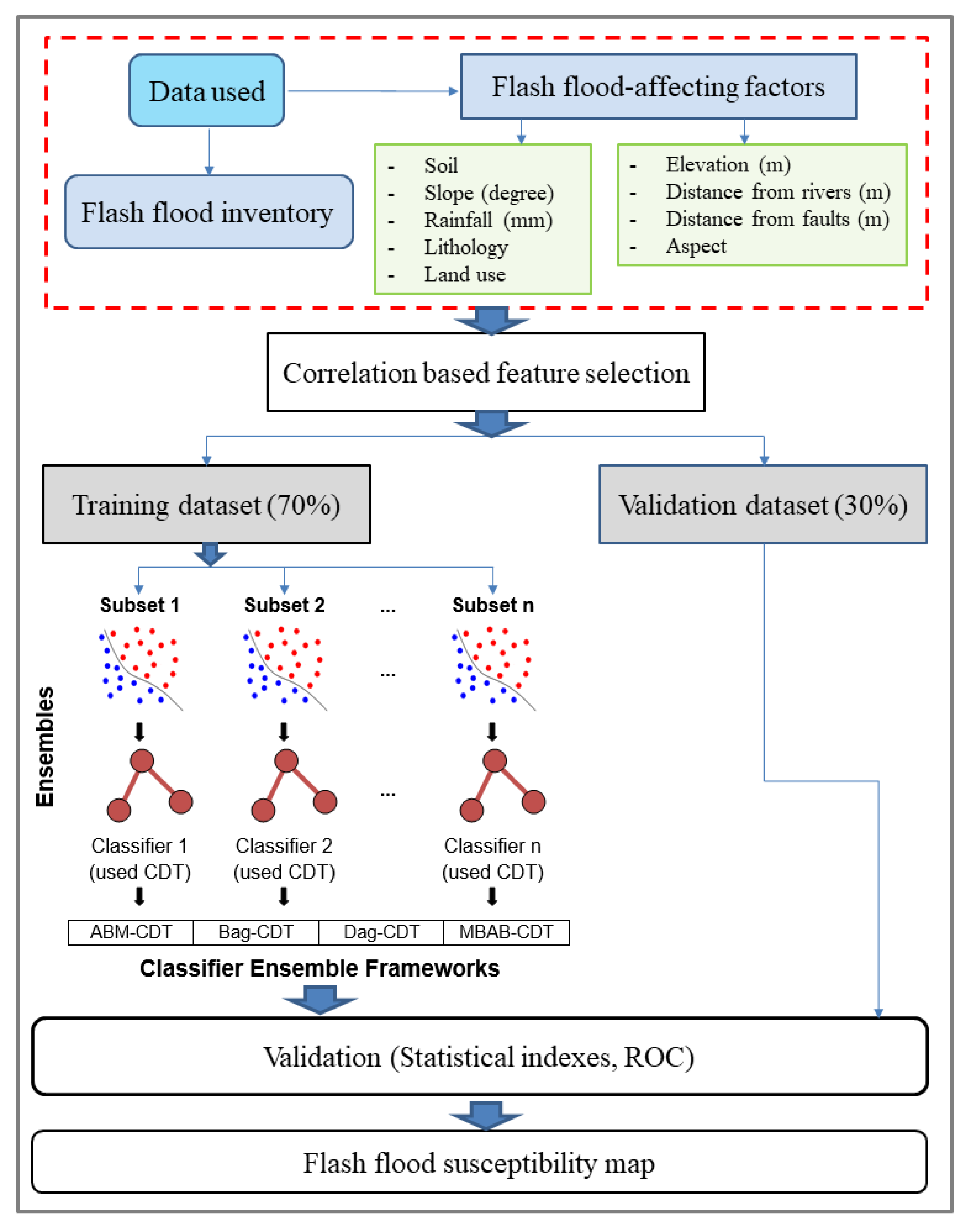
5. Methodology
5.1. Data Collection and Preparation
5.2. Generating Training and Testing Datasets
5.3. Building the Flash Flood Models
5.4. Validation of the Models
5.5. Generation of Flash Flood Susceptibility Maps
6. Results and Discussion
6.1. Impact Weight of each Class of Variables Affecting Flash Flood Susceptibility by FR Method
6.2. Importance of Factors Using Correlation-Based Feature Selection
6.3. Validation of Different Models
6.4. Development of Flash Flood Susceptibility Maps
7. Concluding Remarks
Author Contributions
Funding
Conflicts of Interest
References
- Douben, K.-J. Characteristics of river floods and flooding: A global overview, 1985–2003. Irrig. Drain. J. Int. Comm. Irrig. Drain. 2006, 55, S9–S21. [Google Scholar] [CrossRef]
- Anagnostou, M.N.; Kalogiros, J.; Anagnostou, E.N.; Tarolli, M.; Papadopoulos, A.; Borga, M. Performance evaluation of high-resolution rainfall estimation by X-band dual-polarization radar for flash flood applications in mountainous basins. J. Hydrol. 2010, 394, 4–16. [Google Scholar] [CrossRef]
- Javelle, P.; Fouchier, C.; Arnaud, P.; Lavabre, J. Flash flood warning at ungauged locations using radar rainfall and antecedent soil moisture estimations. J. Hydrol. 2010, 394, 267–274. [Google Scholar] [CrossRef]
- Modrick, T.M.; Georgakakos, K.P. The character and causes of flash flood occurrence changes in mountainous small basins of Southern California under projected climatic change. J. Hydrol. Reg. Stud. 2015, 3, 312–336. [Google Scholar] [CrossRef] [Green Version]
- Das, S. Geospatial mapping of flood susceptibility and hydro-geomorphic response to the floods in Ulhas Basin, India. Remote Sens. Appl. Soc. Environ. 2019, 14, 60–74. [Google Scholar] [CrossRef]
- Bui, D.T.; Tsangaratos, P.; Ngo, P.-T.T.; Pham, T.D.; Pham, B.T. Flash flood susceptibility modeling using an optimized fuzzy rule based feature selection technique and tree based ensemble methods. Sci. Total Environ. 2019, 668, 1038–1054. [Google Scholar] [CrossRef]
- Georgakakos, K.P.; Hudlow, M.D. Quantitative precipitation forecast techniques for use in hydrologic forecasting. Bull. Am. Meteorol. Soc. 1984, 65, 1186–1200. [Google Scholar] [CrossRef]
- Georgakakos, K.P. On the design of national, real-time warning systems with capability for site-specific, flash-flood forecasts. Bull. Am. Meteorol. Soc. 1986, 67, 1233–1239. [Google Scholar] [CrossRef]
- Collier, C.G. Flash flood forecasting: What are the limits of predictability? Q. J. R. Meteorol. Soc. J. Atmos. Sci. Appl. Meteorol. Phys. Oceanogr. 2007, 133, 3–23. [Google Scholar] [CrossRef]
- Recanatesi, F.; Petroselli, A.; Ripa, M.N.; Leone, A. Assessment of stormwater runoff management practices and BMPs under soil sealing: A study case in a peri-urban watershed of the metropolitan area of Rome (Italy). J. Environ. Manag. 2017, 201, 6–18. [Google Scholar] [CrossRef]
- Szewrański, S.; Kazak, J.; Szkaradkiewicz, M.; Sasik, J. Flood risk factors in suburban area in the context of climate change adaptation policies—Case study of Wroclaw, Poland. J. Ecol. Eng. 2015, 16, 13–18. [Google Scholar] [CrossRef]
- Tien Bui, D.; Khosravi, K.; Shahabi, H.; Daggupati, P.; Adamowski, J.F.; Melesse, A.M.; Pham, B.T.; Pourghasemi, H.R.; Mahmoudi, M.; Bahrami, S.; et al. Flood spatial modeling in northern Iran using remote sensing and gis: A comparison between evidential belief functions and its ensemble with a multivariate logistic regression model. Remote Sens. 2019, 11, 1589. [Google Scholar] [CrossRef] [Green Version]
- Hammond, M.J.; Chen, A.S.; Djordjević, S.; Butler, D.; Mark, O. Urban flood impact assessment: A state-of-the-art review. Urban Water J. 2015, 12, 14–29. [Google Scholar] [CrossRef] [Green Version]
- Saksena, S.; Merwade, V. Incorporating the effect of DEM resolution and accuracy for improved flood inundation mapping. J. Hydrol. 2015, 530, 180–194. [Google Scholar] [CrossRef] [Green Version]
- Komolafe, A.A.; Herath, S.; Avtar, R. Sensitivity of flood damage estimation to spatial resolution. J. Flood Risk Manag. 2018, 11, 370–381. [Google Scholar] [CrossRef]
- Annis, A.; Nardi, F.; Morrison, R.R.; Castelli, F. Investigating hydrogeomorphic floodplain mapping performance with varying DTM resolution and stream order. Hydrol. Sci. J. 2019, 64, 525–538. [Google Scholar] [CrossRef]
- Khosravi, K.; Pham, B.T.; Chapi, K.; Shirzadi, A.; Shahabi, H.; Revhaug, I.; Prakash, I.; Bui, D.T. A comparative assessment of decision trees algorithms for flash flood susceptibility modeling at Haraz Watershed, Northern Iran. Sci. Total Environ. 2018, 627, 744–755. [Google Scholar] [CrossRef]
- Nikoo, M.; Ramezani, F.; Hadzima-Nyarko, M.; Nyarko, E.K.; Nikoo, M. Flood-routing modeling with neural network optimized by social-based algorithm. Nat. Hazards 2016, 82, 1–24. [Google Scholar] [CrossRef]
- Pradhan, B.; Shafiee, M.; Pirasteh, S. Maximum flash flood prone area mapping using RADARSAT images and GIS: Kelantan river basin. Int. J. Geoinform. 2009, 5, 11–23. [Google Scholar]
- Noman, N.S.; Nelson, E.J.; Zundel, A.K. Review of automated floodplain delineation from digital terrain models. J. Water Resour. Plan. Manag. 2001, 127, 394–402. [Google Scholar] [CrossRef]
- Papaioannou, G.; Vasiliades, L.; Loukas, A. Multi-criteria analysis framework for potential flash flood prone areas mapping. Water Resour. Manag. 2015, 29, 399–418. [Google Scholar] [CrossRef]
- Bui, D.T.; Hoang, N.-D. A bayesian framework based on a gaussian mixture model and radial-basis-function fisher discriminant analysis (BayGmmKda V1. 1) for spatial prediction of floods. Geosci. Model Dev. 2017, 10, 3391. [Google Scholar]
- Brunner, G.W. HEC-RAS River Analysis System. Hydraulic Reference Manual, Version 1.0; Hydrologic Engineering Center: Davis, CA, USA, 1995. [Google Scholar]
- Bui, D.T.; Ngo, P.-T.T.; Pham, T.D.; Jaafari, A.; Minh, N.Q.; Hoa, P.V.; Samui, P. A novel hybrid approach based on a swarm intelligence optimized extreme learning machine for flash flood susceptibility mapping. Catena 2019, 179, 184–196. [Google Scholar] [CrossRef]
- Bui, D.T.; Pradhan, B.; Nampak, H.; Bui, Q.-T.; Tran, Q.-A.; Nguyen, Q.-P. Hybrid artificial intelligence approach based on neural fuzzy inference model and metaheuristic optimization for flash flood susceptibilitgy modeling in a high-frequency tropical cyclone area using GIS. J. Hydrol. 2016, 540, 317–330. [Google Scholar]
- Chen, Y.-R.; Yeh, C.-H.; Yu, B. Integrated application of the analytic hierarchy process and the geographic information system for flash flood risk assessment and flash flood plain management in Taiwan. Nat. Hazards 2011, 59, 1261–1276. [Google Scholar] [CrossRef] [Green Version]
- Das, S. Geographic information system and AHP-based flood hazard zonation of Vaitarna Basin, Maharashtra, India. Arab. J. Geosci. 2018, 11, 576. [Google Scholar] [CrossRef]
- Radwan, F.; Alazba, A.A.; Mossad, A. Flash flood risk assessment and mapping using AHP in arid and semiarid regions. Acta Geophys. 2019, 67, 215–229. [Google Scholar] [CrossRef]
- Souissi, D.; Zouhri, L.; Hammami, S.; Msaddek, M.H.; Zghibi, A.; Dlala, M. GIS-based MCDM-AHP modeling for flash flood susceptibility mapping of arid areas, Southeastern Tunisia. Geocarto Int. 2019, 1–27. [Google Scholar]
- Pierdicca, N.; Pulvirenti, L.; Chini, M.; Guerriero, L.; Ferrazzoli, P. A fuzzy-logic-based approach for flash flood detection from cosmo-skymed data. In Proceedings of the IEEE International Geoscience & Remote Sensing Symposium, IGARSS 2010, Honolulu, HI, USA, 25–30 July 2010; pp. 4796–4798. [Google Scholar]
- Zou, Q.; Zhou, J.; Zhou, C.; Song, L.; Guo, J. Comprehensive flash flood risk assessment based on set pair analysis-variable fuzzy sets model and fuzzy AHP. Stoch. Environ. Res. Risk Assess. 2013, 27, 525–546. [Google Scholar] [CrossRef]
- Lee, M.-J.; Kang, J.; Jeon, S. Application of frequency ratio model and validation for predictive flooded area susceptibility mapping using GIS. In Proceedings of the 2012 IEEE International Geoscience and Remote Sensing Symposium, Munich, Germany, 22–27 July 2012; pp. 895–898. [Google Scholar]
- Tehrany, M.S.; Pradhan, B.; Jebur, M.N. Flash flood susceptibility analysis and its verification using a novel ensemble support vector machine and frequency ratio method. Stoch. Environ. Res. Risk Assess. 2015, 29, 1149–1165. [Google Scholar] [CrossRef]
- Yan, J.; Jin, J.; Chen, F.; Yu, G.; Yin, H.; Wang, W. Urban flash flood forecast using support vector machine and numerical simulation. J. Hydro. 2018, 20, 221–231. [Google Scholar] [CrossRef]
- Tehrany, M.S.; Pradhan, B.; Mansor, S.; Ahmad, N. Flash flood susceptibility assessment using GIS-based support vector machine model with different kernel types. Catena 2015, 125, 91–101. [Google Scholar] [CrossRef]
- Sahoo, G.B.; Ray, C.; De Carlo, E.H. Use of neural network to predict flash flood and attendant water qualities of a mountainous stream on Oahu, Hawaii. J. Hydrol. 2006, 327, 525–538. [Google Scholar] [CrossRef]
- Youssef, A.M.; Pradhan, B.; Hassan, A.M. Flash flash flood risk estimation along the St. Katherine Road, Southern Sinai, Egypt using GIS based morphometry and satellite imagery. Environ. Earth Sci. 2011, 62, 611–623. [Google Scholar] [CrossRef]
- Kia, M.B.; Pirasteh, S.; Pradhan, B.; Mahmud, A.R.; Sulaiman, W.N.A.; Moradi, A. An artificial neural network model for flash flood simulation using GIS: Johor River Basin, Malaysia. Environ. Earth Sci. 2012, 67, 251–264. [Google Scholar] [CrossRef]
- Nandi, A.; Mandal, A.; Wilson, M.; Smith, D. Flash flood hazard mapping in Jamaica using principal component analysis and logistic regression. Environ. Earth Sci. 2016, 75, 465. [Google Scholar] [CrossRef]
- Darabi, H.; Choubin, B.; Rahmati, O.; Torabi Haghighi, A.; Pradhan, B.; Kløve, B. Urban flash flood risk mapping using the GARP and QUEST models: A comparative study of machine learning techniques. J. Hydrol. 2019, 569, 142–154. [Google Scholar] [CrossRef]
- Lee, S.; Kim, J.-C.; Jung, H.-S.; Lee, M.J.; Lee, S. Spatial prediction of flash flood susceptibility using random-forest and boosted-tree models in Seoul Metropolitan City, Korea. Geomat. Nat. Hazards Risk 2017, 8, 1185–1203. [Google Scholar] [CrossRef] [Green Version]
- Chapi, K.; Singh, V.P.; Shirzadi, A.; Shahabi, H.; Bui, D.T.; Pham, B.T.; Khosravi, K. A novel hybrid artificial intelligence approach for flash flood susceptibility assessment. Environ. Model. Softw. 2017, 95, 229–245. [Google Scholar] [CrossRef]
- Tehrany, M.S.; Pradhan, B.; Jebur, M.N. Flash flood susceptibility mapping using a novel ensemble weights-of-evidence and support vector machine models in GIS. J. Hydrol. 2014, 512, 332–343. [Google Scholar] [CrossRef]
- Bui, D.T.; Panahi, M.; Shahabi, H.; Singh, V.P.; Shirzadi, A.; Chapi, K.; Khosravi, K.; Chen, W.; Panahi, S.; Li, S.; et al. Novel hybrid evolutionary algorithms for spatial prediction of floods. Sci. Rep. 2018, 8, 15364. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Choubin, B.; Moradi, E.; Golshan, M.; Adamowski, J. An ensemble prediction of flood susceptibility using multivariate discriminant analysis, classification and regression trees, and support vector machines. Sci. Total Environ. 2019, 651, 2087–2096. [Google Scholar] [CrossRef] [PubMed]
- Reager, J.T.; Thomas, B.F.; Famiglietti, J.S. River basin flash flood potential inferred using grace gravity observations at several months lead time. Nat. Geosci. 2014, 7, 588. [Google Scholar] [CrossRef]
- Hoang, L.P.; Biesbroek, R.; Tri, V.P.D.; Kummu, M.; Van Vliet, M.T.H.; Leemans, R.; Kabat, P.; Ludwig, F. Managing flash flood risks in the mekong delta: How to address emerging challenges under climate change and socioeconomic developments. Ambio 2018, 47, 635–649. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fernández, D.S.; Lutz, M.A. Urban flash flood hazard zoning in Tucumán Province, Argentina, using GIS and multicriteria decision analysis. Eng. Geol. 2010, 111, 90–98. [Google Scholar] [CrossRef]
- Dahri, N.; Abida, H. Monte carlo simulation-aided Analytical Hierarchy Process (AHP) for flash flood susceptibility mapping in Gabes Basin (Southeastern Tunisia). Environ. Earth Sci. 2017, 76, 302. [Google Scholar] [CrossRef]
- Tehrany, M.S.; Pradhan, B.; Jebur, M.N. Spatial prediction of flash flood susceptible areas using rule based Decision Tree (DT) and a novel ensemble bivariate and multivariate statistical models in GIS. J. Hydrol. 2013, 504, 69–79. [Google Scholar] [CrossRef]
- Li, K.; Wu, S.; Dai, E.; Xu, Z. Flash flood loss analysis and quantitative risk assessment in China. Nat. Hazards 2012, 63, 737–760. [Google Scholar] [CrossRef]
- Garcia-Ruiz, J.M.; Regüés, D.; Alvera, B.; Lana-Renault, N.; Serrano-Muela, P.; Nadal-Romero, E.; Navas, A.; Latron, J.; Marti-Bono, C.; Arnáez, J. Flash flood generation and sediment transport in experimental catchments affected by land use changes in the central pyrenees. J. Hydrol. 2008, 356, 245–260. [Google Scholar] [CrossRef] [Green Version]
- Benito, G.; Rico, M.; Sánchez-Moya, Y.; Sopeña, A.; Thorndycraft, V.R.; Barriendos, M. The impact of late holocene climatic variability and land use change on the flash flood hydrology of the Guadalentin River, Southeast Spain. Glob. Planet. Chang. 2010, 70, 53–63. [Google Scholar] [CrossRef] [Green Version]
- Xu, Y.; Chung, S.-L.; Jahn, B.; Wu, G. Petrologic and geochemical constraints on the petrogenesis of Permian-Triassic Emeishan flash flood basalts in Southwestern China. Lithos 2001, 58, 145–168. [Google Scholar] [CrossRef]
- Kazakis, N.; Kougias, I.; Patsialis, T. Assessment of flash flood hazard areas at a regional scale using an index-based approach and analytical hierarchy process: Application in Rhodope-Evros Region, Greece. Sci. Total Environ. 2015, 538, 555–563. [Google Scholar] [CrossRef] [PubMed]
- Rahmati, O.; Pourghasemi, H.R.; Zeinivand, H. Flood susceptibility mapping using frequency ratio and weights-of-evidence models in the Golastan Province, Iran. Geocarto Int. 2016, 31, 42–70. [Google Scholar] [CrossRef]
- Hall, M.A. Correlation-based feature selection of discrete and numeric class machine learning. In Proceedings of the Seventeenth International Conference on Machine Learning (ICML 2000), Stanford, CA, USA, 29 June–2 July 2000. [Google Scholar]
- Pham, B.T.; Pradhan, B.; Bui, D.T.; Prakash, I.; Dholakia, M.B. A comparative study of different machine learning methods for landslide susceptibility assessment: A case study of Uttarakhand area (India). Environ. Model. Softw. 2016, 84, 240–250. [Google Scholar] [CrossRef]
- Duma, M.; Twala, B.; Nelwamondo, F.V.; Marwala, T. Partial imputation to improve predictive modelling in insurance risk classification using a hybrid positive selection algorithm and correlation-based feature selection. Curr. Sci. 2012, 103, 697–705. [Google Scholar]
- Freund, Y.; Schapire, R.E. A decision-theoretic generalization of on-line learning and an application to boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef] [Green Version]
- Pham, B.T.; Bui, D.T.; Prakash, I.; Dholakia, M.B. Hybrid integration of multilayer perceptron neural networks and machine learning ensembles for landslide susceptibility assessment at Himalayan Area (India) using GIS. Catena 2017, 149, 52–63. [Google Scholar] [CrossRef]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef] [Green Version]
- Piao, Y.; Piao, M.; Jin, C.H.; Shon, H.S.; Chung, J.-M.; Hwang, B.; Ryu, K.H. A new ensemble method with feature space partitioning for high-dimensional data classification. Math. Probl. Eng. 2015, 2015, 1–12. [Google Scholar] [CrossRef] [Green Version]
- He, Q.; Xu, Z.; Li, S.; Li, R.; Zhang, S.; Wang, N.; Pham, B.T.; Chen, W. Novel entropy and rotation forest-based credal decision tree classifier for landslide susceptibility modeling. Entropy 2019, 21, 106. [Google Scholar] [CrossRef] [Green Version]
- Khosravi, K.; Cooper, J.R.; Daggupati, P.; Pham, B.T.; Bui, D.T. Bedload transport rate prediction: Application of novel hybrid data mining techniques. J. Hydrol. 2020, 124774. [Google Scholar] [CrossRef]
- Ting, K.M.; Witten, I.H. Stacking bagged and dagged models. In Proceedings of the 14th International Conference on Machine Learning, San Francisco, CA, USA, 8–12 July 1997. [Google Scholar]
- Onan, A.; Korukouglu, S.; Bulut, H. Ensemble of keyword extraction methods and classifiers in text classification. Expert Syst. Appl. 2016, 57, 232–247. [Google Scholar] [CrossRef]
- Thai, B.; Dieu, P.; Bui, T.; Prakash, I. Landslide susceptibility assessment using bagging ensemble based alternating decision trees, logistic regression and J48 decision trees methods: A comparative study. Geotech. Geol. Eng. 2017, 35, 2597–2611. [Google Scholar] [CrossRef]
- Webb, G.I. Multiboosting: A technique for combining boosting and wagging. Mach. Learn. 2000, 40, 159–196. [Google Scholar] [CrossRef] [Green Version]
- Kotti, M.; Benetos, E.; Kotropoulos, C.; Pitas, I. A neural network approach to audio-assisted movie dialogue detection. Neurocomputing 2007, 71, 157–166. [Google Scholar] [CrossRef] [Green Version]
- Bui, D.T.; Ho, T.-C.; Pradhan, B.; Pham, B.-T.; Nhu, V.-H.; Revhaug, I. GIS-based modeling of rainfall-induced landslides using data mining-based functional trees classifier with adaboost, bagging, and multiboost ensemble frameworks. Environ. Earth Sci. 2016, 75, 1101. [Google Scholar]
- Abellán, J.; Moral, S. Building classification trees using the total uncertainty criterion. Int. J. Intell. Syst. 2003, 18, 1215–1225. [Google Scholar] [CrossRef] [Green Version]
- Mantas, C.J.; Abellán, J. Credal-C4.5: Decision tree based on imprecise probabilities to classify noisy data. Expert Syst. Appl. 2014, 41, 4625–4637. [Google Scholar] [CrossRef]
- Abellán, J.; Masegosa, A.R. Combining decision trees based on imprecise probabilities and uncertainty measures. In European Conference on Symbolic and Quantitative Approaches to Reasoning and Uncertainty; Springer: Berlin/Heidelberg, Germany, 2007; pp. 512–523. [Google Scholar]
- Dempster, A.P. Upper and lower probabilities induced by a multivalued mapping. In Classic Works of the Dempster-Shafer Theory of Belief Functions; Springer: New York, NY, USA, 2008; pp. 57–72. [Google Scholar]
- Shafer, G. A Mathematical Theory of Evidence; Princeton University Press: Princeton, NJ, USA, 1976; p. 42. [Google Scholar]
- Abellan, J.; Moral, S. Completing a total uncertainty measure in the dempster-shafer theory. Int. J. Gen. Syst. 1999, 28, 299–314. [Google Scholar] [CrossRef]
- Abellan, J.; Moral, S. A non-specificity measure for convex sets of probability distributions. Int. J. Uncertain. Fuzziness Knowl. Based Syst. 2000, 8, 357–367. [Google Scholar] [CrossRef]
- Mantas, C.J.; Abellán, J.; Castellano, J.G. Analysis of credal-C4. 5 for classification in noisy domains. Expert Syst. Appl. 2016, 61, 314–326. [Google Scholar] [CrossRef]
- Walley, P. Inferences from multinomial data: Learning about a bag of marbles. J. R. Stat. Soc. Ser. B 1996, 58, 3–34. [Google Scholar] [CrossRef]
- Mantas, C.J.; Abellán, J. Analysis and extension of decision trees based on imprecise probabilities: Application on noisy data. Expert Syst. Appl. 2014, 41, 2514–2525. [Google Scholar] [CrossRef]
- Hong, H.; Panahi, M.; Shirzadi, A.; Ma, T.; Liu, J.; Zhu, A.-X.; Chen, W.; Kougias, I.; Kazakis, N. Flash flood susceptibility assessment in hengfeng area coupling adaptive neuro-fuzzy inference system with genetic algorithm and differential evolution. Sci. Total Environ. 2018, 621, 1124–1141. [Google Scholar] [CrossRef] [PubMed]
- Pham, B.T.; Bui, D.T.; Dholakia, M.B.; Prakash, I.; Pham, H.V. A comparative study of least square support vector machines and multiclass alternating decision trees for spatial prediction of rainfall-induced landslides in a tropical cyclones area. Geotech. Geol. Eng. 2016, 34, 1807–1824. [Google Scholar] [CrossRef]
- Ayalew, L.; Yamagishi, H.; Ugawa, N. Landslide susceptibility mapping using GIS-based weighted linear combination, the case in Tsugawa Area of Agano River, Niigata Prefecture, Japan. Landslides 2004, 1, 73–81. [Google Scholar] [CrossRef]
- Van Dao, D.; Jaafari, A.; Bayat, M.; Mafi-Gholami, D.; Qi, C.; Moayedi, H.; Van Phong, T.; Ly, H.-B.; Le, T.-T.; Trinh, P.T. A spatially explicit deep learning neural network model for the prediction of landslide susceptibility. Catena 2020, 188, 104451. [Google Scholar]
- Termeh, S.V.R.; Khosravi, K.; Sartaj, M.; Keesstra, S.D.; Tsai, F.T.C.; Dijksma, R.; Pham, B.T. Optimization of an adaptive neuro-fuzzy inference system for groundwater potential mapping. Hydrogeol. J. 2019, 27, 2511–2534. [Google Scholar] [CrossRef]
- Pham, B.T.; Jaafari, A.; Prakash, I.; Singh, S.K.; Quoc, N.K.; Bui, D.T. Hybrid computational intelligence models for groundwater potential mapping. Catena 2019, 182, 104101. [Google Scholar] [CrossRef]
- Tien Bui, D.; Shirzadi, A.; Chapi, K.; Shahabi, H.; Pradhan, B.; Pham, B.T.; Singh, V.P.; Chen, W.; Khosravi, K.; Ahmad, B.B.; et al. A hybrid computational intelligence approach to groundwater spring potential mapping. Water 2019, 11, 2013. [Google Scholar] [CrossRef] [Green Version]
- Phong, T.V.; Phan, T.T.; Prakash, I.; Singh, S.K.; Shirzadi, A.; Chapi, K.; Ly, H.B.; Ho, L.S.; Quoc, N.K.; Pham, B.T. Landslide susceptibility modeling using different artificial intelligence methods: A case study at Muong Lay district, Vietnam. Geocarto Int. 2019. [Google Scholar] [CrossRef]
- Tien Bui, D.; Shirzadi, A.; Shahabi, H.; Geertsema, M.; Omidvar, E.; Clague, J.J.; Thai Pham, B.; Dou, J.; Talebpoor, D.; Lee, S.; et al. New ensemble models for shallow landslide susceptibility modeling in a semi-arid watershed. Forests 2019, 10, 743. [Google Scholar] [CrossRef] [Green Version]
- Pham, B.T.; Prakash, I.; Singh, S.K.; Shirzadi, A.; Shahabi, H.; Bui, D.T. Landslide susceptibility modeling using Reduced Error Pruning Trees and different ensemble techniques: Hybrid machine learning approaches. Catena 2019, 175, 203–218. [Google Scholar] [CrossRef]
- Pham, B.T.; Bui, D.T.; Pham, H.V.; Le, H.Q.; Prakash, I.; Dholakia, M.B. Landslide hazard assessment using random subspace fuzzy rules based classifier ensemble and probability analysis of rainfall data: A case study at Mu Cang Chai District, Yen Bai Province (Viet Nam). J. Indian Soc. Remote Sens. 2017, 45, 673–683. [Google Scholar] [CrossRef]
- Jaafari, A.; Zenner, E.K.; Pham, B.T. Wildfire spatial pattern analysis in the Zagros Mountains, Iran: A comparative study of decision tree based classifiers. Ecol. Inform. 2018, 43, 200–211. [Google Scholar] [CrossRef]
- Khosravi, K.; Shahabi, H.; Pham, B.T.; Adamowski, J.; Shirzadi, A.; Pradhan, B.; Dou, J.; Ly, H.; Grof, G.; Ho, H.L.; et al. A comparative assessment of flood susceptibility modeling using multi-criteria decision making analysis and machine learning methods. J. Hydrol. 2019, 573, 311–323. [Google Scholar] [CrossRef]
- Khosravi, K.; Sartaj, M.; Tsai, F.T.; Singh, V.P.; Kazakis, N.; Melesse, A.M.; Prakash, I.; Bui, D.T.; Pham, B.T. A comparison study of drastic methods with various objective methods for groundwater vulnarability assessment. Sci. Total Environ. 2018, 642, 1032–1049. [Google Scholar] [CrossRef]
- Miraki, S.; Zanganeh, S.H.; Chapi, K.; Singh, V.P.; Shirzadi, A.; Shahabi, H.; Pham, B.T. Mapping groundwater potential using a novel hybrid intelligence approach. Water Resour. Manag. 2019, 33, 281–302. [Google Scholar] [CrossRef]
- Dou, J.; Yunus, A.P.; Bui, D.T.; Merghadi, A.; Sahana, M.; Zhu, Z.; Chen, C.; Khosravi, K.; Yang, Y.; Pham, B.T. Assessment of advanced random forest and decision tree algorithms for modeling rainfall-induced landslide susceptibility in the Izu-Oshima Volcanic Island, Japan. Sci. Total Environ. 2019, 662, 332–346. [Google Scholar] [CrossRef]
- Abedini, M.; Ghasemian, B.; Shirzadi, A.; Shahabi, H.; Chapi, K.; Pham, B.T.; Ahmad, B.B.; Tien Bui, D. A novel hybrid approach of bayesian logistic regression and its ensembles for landslide susceptibility assessment. Geocarto Int. 2018. [Google Scholar] [CrossRef]
- Chang, K.T.; Merghadi, A.; Yunus, A.P.; Pham, B.T.; Dou, J. Evaluating scale effects of topographic variables in landslide susceptibility models using GIS-based machine learning techniques. Sci. Rep. 2019, 9, 1–21. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nohani, E.; Moharrami, M.; Sharafi, S.; Khosravi, K.; Pradhan, B.; Pham, B.T.; Lee, S.; Melesse, A.M. Landslide susceptibility mapping using different GIS-based bivariate models. Water 2019, 11, 1402. [Google Scholar] [CrossRef] [Green Version]
- Pham, B.T.; Nguyen, M.D.; Bui, K.T.; Prakash, I.; Chapi, K.; Bui, D.T. A novel artificial intelligence approach based on multi-layer perceptron neural network and biogeography based optimization for predicting coefficient of consolidation of soil. Catena 2019, 173, 302–311. [Google Scholar] [CrossRef]
- Nguyen, V.V.; Pham, B.T.; Vu, B.T.; Prakash, I.; Jha, S.; Shahabi, H.; Shirzadi, A.; Ba, D.N.; Kumar, R.; Chatterjee, J.M.; et al. Hybrid machine learning approaches for landslide susceptibility modelling. Forests 2019, 10, 157. [Google Scholar] [CrossRef] [Green Version]
- Pham, B.T.; Prakash, I.; Jaafari, A.; Bui, D.T. Spatial prediction of rainfall-induced landslides using aggregating one-dependence estimators classifier. J. Indian Soc. Remote Sens. 2018, 46, 1457–1470. [Google Scholar] [CrossRef]
- Pham, B.T.; Prakash, I. A novel hybrid model of bagging-based naïve bayes trees for landslide susceptibility. Bull. Eng. Geol. Environ. 2019, 78, 1911–1925. [Google Scholar] [CrossRef]
- Pham, B.T. A novel classifier based on composite hyper-cubes on iterated random projections for assessment of landslide susceptibility. J. Geol. Soc. India 2018, 91, 355–362. [Google Scholar] [CrossRef]
- Dou, J.; Yunus, A.P.; Xu, Y.; Zhu, Z.; Chen, C.W.; Sahana, M.; Yang, Y.; Khosravi, K.; Pham, B.T. Torrential rainfall-triggered shallow landslide characteristics and susceptibility assessment using ensemble data-driven models in the Dongjiang Reservoir Watershed, China. Nat. Hazards 2019, 97, 579–609. [Google Scholar] [CrossRef]
- Pham, B.T.; Prakash, I.; Dou, J.; Singh, S.K.; Trinh, P.T.; Tran, H.T.; Le, T.M.; Phong, T.V.; Khoi, D.K.; Shirzadi, A.; et al. A novel hybrid approach of landslide susceptibility modelling using rotation forest ensemble and different base classifiers. Geocarto Int. 2019, 1–25. [Google Scholar] [CrossRef]
- Peng, Y.; Shi, Y.; Yan, H.; Chen, K.; Zhang, J. Coincidence risk analysis of floods using multivariate copulas: Case study of Jinsha River and Min River, China. J. Hydrol. Eng. 2018, 24, 05018030. [Google Scholar] [CrossRef]
- Le, L.M.; Ly, H.B.; Pham, B.T.; Le, V.M.; Pham, T.A.; Nguyen, D.H.; Tran, X.T.; Le, T.T. Hybrid artificial intelligence approaches for predicting buckling damage of steel columns under axial compression. Materials 2019, 12, 1670. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ly, H.B.; Desceliers, C.; Le, L.M.; Le, T.T.; Pham, B.T.; Nguyen-Ngoc, L.; Doan, V.T.; Le, M. Quantification of uncertainties on the critical buckling load of columns under axial compression with uncertain random materials. Materials 2019, 12, 1828. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shahabi, H.; Jarihani, B.; Tavakkoli Piralilou, S.; Chittleborough, D.; Avand, M.; Ghorbanzadeh, O. A semi-automated object-based gully networks detection using different machine learning models: A case study of Bowen Catchment, Queensland, Australia. Sensors 2019, 19, 4893. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jalayer, F.; De Risi, R.; De Paola, F.; Giugni, M.; Manfredi, G.; Gasparini, P.; Topa, M.E.; Yonas, N.; Yeshitela, K.; Nebebe, A.; et al. Probabilistic GIS-based method for delineation of urban flooding risk hotspots. Nat. Hazards 2014, 73, 975–1001. [Google Scholar] [CrossRef]
- Chapman, L. Increasing vulnerability to floods in new development areas: Evidence from Ho Chi Minh City. Int. J. Clim. Chang. Strateg. Manag. 2018. [Google Scholar] [CrossRef]
- Dano, U.L.; Balogun, A.L.; Matori, A.N.; Wan Yusouf, K.; Rimi Abubakar, I.; Mohamed, S.; Aina, Y.A.; Pradhan, B. Flood susceptibility mapping using GIS-based analytic network process: A case study of Perlis, Malaysia. Water 2019, 11, 615. [Google Scholar] [CrossRef] [Green Version]
- Zhao, G.; Pang, B.; Xu, Z.; Peng, D.; Xu, L. Assessment of urban flood susceptibility using semi-supervised machine learning model. Sci. Total Environ. 2019, 659, 940–949. [Google Scholar] [CrossRef]
- Khosravi, K.; Melesse, A.M.; Shahabi, H.; Shirzadi, A.; Chapi, K.; Hong, H. Flood susceptibility mapping at Ningdu catchment, China using bivariate and data mining techniques. In Extreme Hydrology and Climate Variability; Elsevier: London, UK, 2019; pp. 419–434. [Google Scholar]
- Termeh, S.V.R.; Kornejady, A.; Pourghasemi, H.R.; Keesstra, S. Flood susceptibility mapping using novel ensembles of adaptive neuro fuzzy inference system and metaheuristic algorithms. Sci. Total Environ. 2018, 615, 438–451. [Google Scholar] [CrossRef]
- Ahmadlou, M.; Karimi, M.; Alizadeh, S.; Shirzadi, A.; Parvinnejhad, D.; Shahabi, H.; Panahi, M. Flood susceptibility assessment using integration of adaptive network-based fuzzy inference system (ANFIS) and biogeography-based optimization (BBO) and BAT algorithms (BA). Geocarto Int. 2019, 34, 1252–1272. [Google Scholar] [CrossRef]
- Thai Pham, B.; Tien Bui, D.; Prakash, I. Landslide susceptibility modelling using different advanced decision trees methods. Civil Eng. Environ. Syst. 2018, 35, 139–157. [Google Scholar] [CrossRef]
- Li, H.; Ouyang, J.; Li, F.; Xie, X. Study on safety evaluation model of small and medium-sized earth-rock dam based on BP-AdaBoost algorithm. In IOP Conference Series: Materials Science and Engineering; IOP Publishing: Bristol, UK, 2019; p. 032024. [Google Scholar]
- Avand, M.; Janizadeh, S.; Tien Bui, D.; Pham, V.H.; Ngo, P.T.T.; Nhu, V.H. A tree-based intelligence ensemble approach for spatial prediction of potential groundwater. Int. J. Digital Earth 2020, 1–22. [Google Scholar] [CrossRef]
- Kuncheva, L. Combining Pattern Classifiers Methods and Algorithms; John Wiley&Sons. Inc. Publication: Hoboken, NI, USA, 2014. [Google Scholar]
- Thai Pham, B.; Shirzadi, A.; Shahabi, H.; Omidvar, E.; Singh, S.K.; Sahana, M.; Asl, D.T.; Ahmad, B.B.; Quoc, N.K.; Lee, S. Landslide susceptibility assessment by novel hybrid machine learning algorithms. Sustainability 2019, 11, 4386. [Google Scholar] [CrossRef] [Green Version]
- Dou, J.; Yunus, A.P.; Bui, D.T.; Merghadi, A.; Sahana, M.; Zhu, Z.; Chen, C.; Han, Z.; Pham, B.T. Improved landslide assessment using support vector machine with bagging, boosting, and stacking ensemble machine learning framework in a mountainous watershed, Japan. Landslides 2019. [Google Scholar] [CrossRef]
- Merghadi, A.; Abderrahmane, B.; Tien Bui, D. Landslide susceptibility assessment at Mila Basin (Algeria): A comparative assessment of prediction capability of advanced machine learning methods. ISPRS Int. J. Geo-Inf. 2019, 7, 268. [Google Scholar] [CrossRef] [Green Version]
- Gautam, D.; Dong, Y. Multi-hazard vulnerability of structures and lifelines due to the 2015 Gorkha earthquake and 2017 central Nepal flash flood. J. Build. Eng. 2018, 17, 196–201. [Google Scholar] [CrossRef]
- Eem, S.-h.; Yang, B.-j.; Jeon, H. Simplified methodology for urban flood damage assessment at building scale using open data. J. Coast. Res. 2018, 85, 1396–1400. [Google Scholar] [CrossRef] [Green Version]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Row | Primary Input Data | Original Format Sources | Spatial Resolution | Source of Data | Derived Map |
|---|---|---|---|---|---|
| 1 | ALOS-PALSER DEM | Raster | 12.5 m | https://search.asf.alaska.edu/ | Slope, Aspect, Curvature, Elevation, Distance from river |
| 2 | Landsat 8 OLI | Raster | 30 m | Department of Natural Resources of Markazi Province | Land use map |
| 3 | Meteorological data | Point | - | Markazi County Meteorological Bureau | Rainfall map |
| 4 | Geological map | Vector | 1:100000 | Geological survey and Mineral Exploration of Iran | Lithology and Distance from fault |
| 5 | Soil map | Vector | 1:100000 | Department of Natural Resources of Markazi Province | Soil map |
| Group No | Geo-Units | Description | Permeability |
|---|---|---|---|
| 1 | Ea.bvt | Andesitic to basaltic volcanic tuff | Low |
| 2 | OMc | Basal conglomerate and sandstone | Moderate |
| 3 | Ed.avs | Dacitic to andesitic volcanosediment | Moderate |
| 4 | TRJs | Dark grey shale and sandstone (SHEMSHAK FM.) | Moderate |
| 5 | EKgy | Gypsum | High |
| 6 | K2I1 | Hyporite bearing limestone (Senonian) | Moderate |
| 7 | OMq | Limestone, marl, gypsiferous marl. Sandymarl and sandstone (QOM FM) | Low |
| 8 | Qft2 | Low level piedment fan and valley terrace deposit | High |
| 9 | Plc | Polymictic conglomerate and sandstone | Moderate |
| 10 | Mur | Red marl, gypsiferous marl, sandstone and conglomerate (upper red Fm.) | High |
| 11 | TRn | Sandstone, quartze arenite, shale and fossiliferous limestone (NAIBAND for) | Moderate |
| 12 | K2shm | Sale calcareous shale and sandstone with intercalations of limestone | Moderate |
| 13 | Ktzl | Thick bedded to massive, white to pinkish orbitolina bearing limestone (TIZKUh FM) | Moderate |
| 14 | Judi | Upper Jurassic diorite | Low |
| 15 | EK | Well bedded green tuff and tuffaceousshle (KARAJ FM) | Moderate |
| Statistical Measures | Formula |
|---|---|
| PPV (%) | |
| NPV (%) | |
| ACC (%) | |
| SST (%) | SST = |
| SPF (%) | SPF = |
| k | Pa = (A + C) Pest = (A + D) × (A + D) + (B + C) × (D + C) |
| Ranked | Class | Average Merit (AM) |
|---|---|---|
| 1 | Distance from rivers | 0.608 |
| 2 | Slope | 0.484 |
| 3 | Elevation | 0.337 |
| 4 | Lithology | 0.125 |
| 5 | Soil | 0.099 |
| 6 | Rainfall | 0.049 |
| 7 | Land use | 0.024 |
| 8 | Aspect | 0.022 |
| 9 | Distance from faults | 0.007 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pham, B.T.; Avand, M.; Janizadeh, S.; Phong, T.V.; Al-Ansari, N.; Ho, L.S.; Das, S.; Le, H.V.; Amini, A.; Bozchaloei, S.K.; et al. GIS Based Hybrid Computational Approaches for Flash Flood Susceptibility Assessment. Water 2020, 12, 683. https://doi.org/10.3390/w12030683
Pham BT, Avand M, Janizadeh S, Phong TV, Al-Ansari N, Ho LS, Das S, Le HV, Amini A, Bozchaloei SK, et al. GIS Based Hybrid Computational Approaches for Flash Flood Susceptibility Assessment. Water. 2020; 12(3):683. https://doi.org/10.3390/w12030683
Chicago/Turabian StylePham, Binh Thai, Mohammadtaghi Avand, Saeid Janizadeh, Tran Van Phong, Nadhir Al-Ansari, Lanh Si Ho, Sumit Das, Hiep Van Le, Ata Amini, Saeid Khosrobeigi Bozchaloei, and et al. 2020. "GIS Based Hybrid Computational Approaches for Flash Flood Susceptibility Assessment" Water 12, no. 3: 683. https://doi.org/10.3390/w12030683