A Hybrid Computational Intelligence Approach to Groundwater Spring Potential Mapping

 , ,
, ,  ,
,  ,
,  , , ,
, , , 
Abstract
:1. Introduction
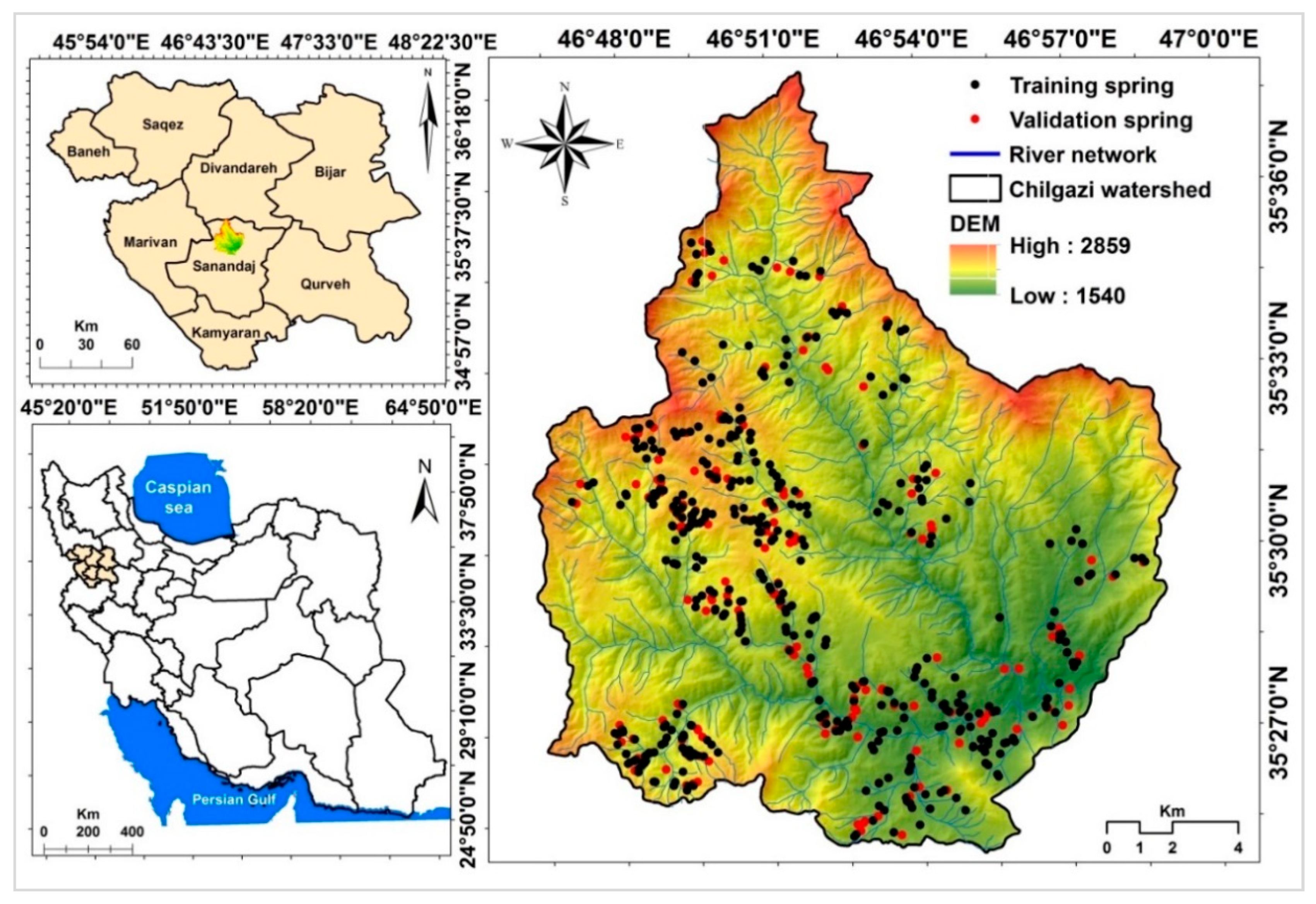
2. Research Area and Groundwater Spring Geodatabase
Description of Research Area
3. Data Acquisition
3.1. Data Collection and Interpretation
3.2. Groundwater Spring Conditioning Factors
3.2.1. Topographic Factors
3.2.2. Hydrological Factors
3.2.3. Geological Factors
3.2.4. Land Cover Factors
4. Theoretical Background of Machine Learning Algorithms
4.1. Logistic Regression (LR)
4.2. Logistic Model Tree (LMT)
4.3. Stochastic Gradient Descent (SGD)
4.4. Support Vector Machine (SVM)
4.5. Alternating Decision Tree (ADTree)
4.6. Random Forest (RF)
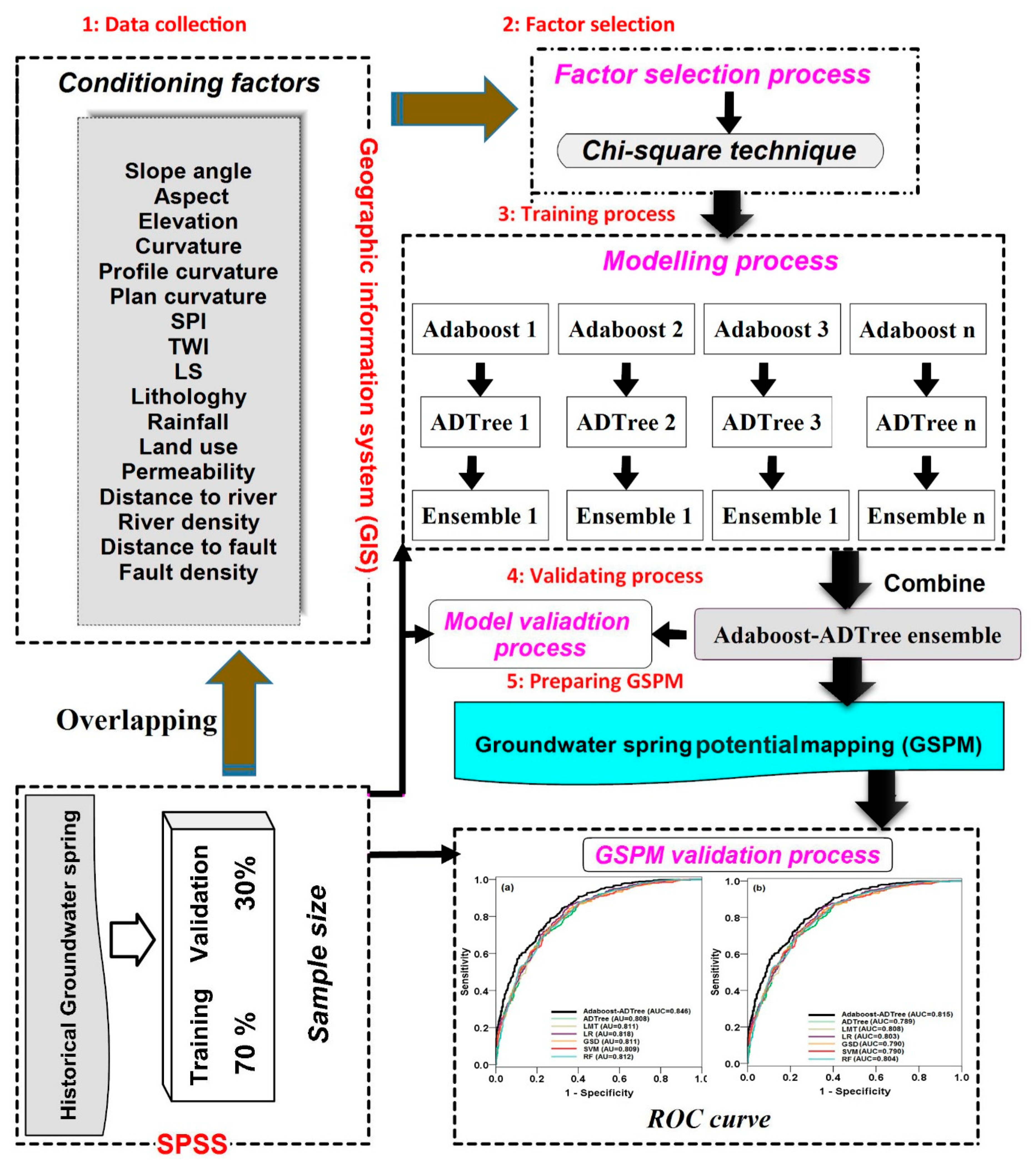
4.7. AB Learning Ensemble Techniques
“AB–ADTree” Model
4.8. Accuracy Assessment (Validation) and Comparison of Methods
4.8.1. Statistical Measures
4.8.2. Receiver Operating Characteristics Curve (ROC)
4.8.3. Statistical Assessment
4.9. Selection of Training Factors Using Chi-Square Technique
5. Results and Analysis
5.1. Groundwater Spring Conditioning Factor Analysis
5.2. Model Training and Assessment
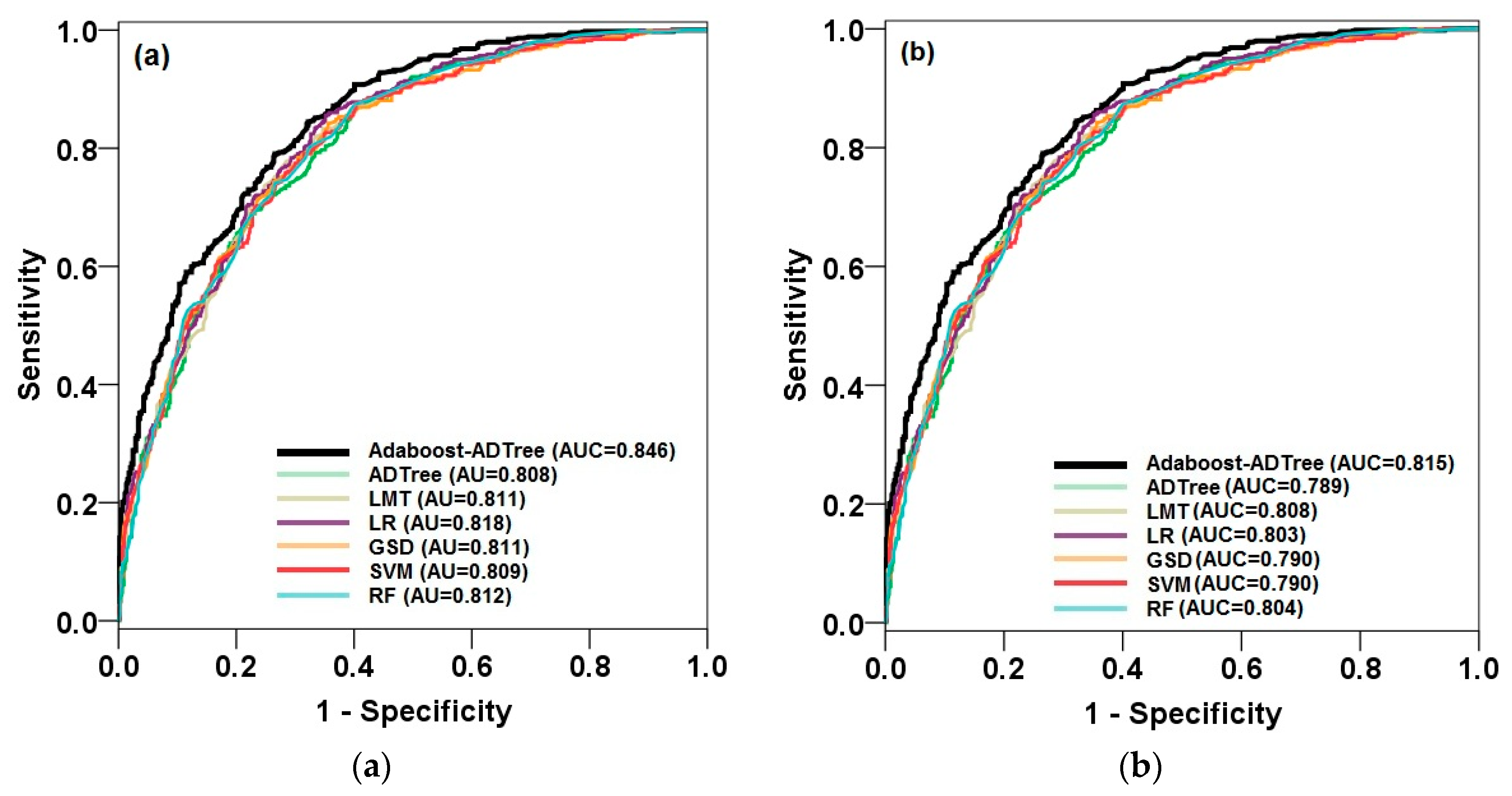
5.3. Models Validation and Comparison
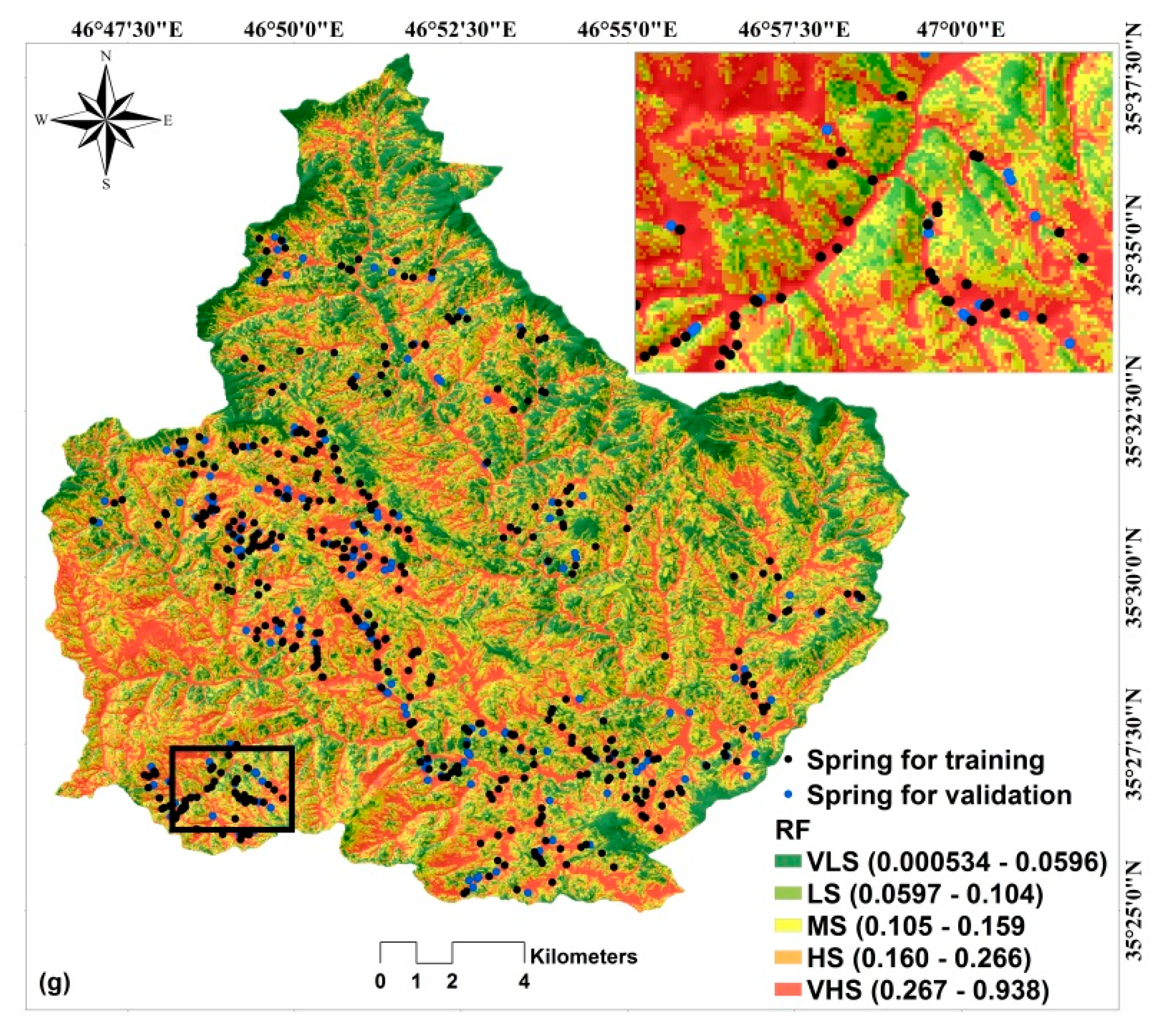
5.4. Groundwater Spring Potential Mapping
5.5. GSPM Validation and Comparison
5.6. Similarities Between Prediction Power of Models
6. Discussion
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Ayazi, M.H.; Pirasteh, S.; Arvin, A.; Pradhan, B.; Nikouravan, B.; Mansor, S. Disasters and risk reduction in groundwater: Zagros Mountain Southwest Iran using geoinformatics techniques. Disaster Adv. 2010, 3, 51–57. [Google Scholar]
- Neshat, A.; Pradhan, B.; Pirasteh, S.; Shafri, H.Z.M. Estimating groundwater vulnerability to pollution using a modified DRASTIC model in the Kerman agricultural area, Iran. Environ. Earth Sci. 2014, 71, 3119–3131. [Google Scholar] [CrossRef]
- Banks, D.; Robins, N.; Robins, N. An Introduction to Groundwater in Crystalline Bedrock; Norges geologiske undersøkelse: Trondheim, Norway, 2002. [Google Scholar]
- Saraf, A.; Choudhury, P. Integrated remote sensing and GIS for groundwater exploration and identification of artificial recharge sites. Int. J. Remote Sens. 1998, 19, 1825–1841. [Google Scholar] [CrossRef]
- BGR. Federal Institute for Geosciences and Natural Resources. Available online: http://www.bgr.bund.de (accessed on 12 July 2011).
- Arkoprovo, B.; Adarsa, J.; Prakash, S.S. Delineation of groundwater potential zones using satellite remote sensing and geographic information system techniques: A case study from Ganjam district, Orissa, India. Res. J. Recent Sci. 2012, 9, 59–66. [Google Scholar]
- Rahmati, O. An Investigation of Quantitative Zonation and Groundwater Potential (Case Study: Ghorveh-Dehgolan plain). Master’s Thesis, Tehran University, Tehran, Iran, 2013. [Google Scholar]
- Ghayoumian, J.; Saravi, M.M.; Feiznia, S.; Nouri, B.; Malekian, A. Application of GIS techniques to determine areas most suitable for artificial groundwater recharge in a coastal aquifer in southern Iran. J. Asian Earth Sci. 2007, 30, 364–374. [Google Scholar] [CrossRef]
- Abbaspour, K.C.; Faramarzi, M.; Ghasemi, S.S.; Yang, H. Assessing the impact of climate change on water resources in Iran. Water Resour. Res. 2009, 45, 1–16. [Google Scholar] [CrossRef]
- Zarghami, M.; Abdi, A.; Babaeian, I.; Hassanzadeh, Y.; Kanani, R. Impacts of climate change on runoffs in East Azerbaijan, Iran. Glob. Planet. Chang. 2011, 78, 137–146. [Google Scholar] [CrossRef]
- Hosseini, M.; Ghafouri, A.M.; Amin, M.; Tabatabaei, M.; Goodarzi, M.; Abde Kolahchi, A. Effects of land use changes on water balance in Taleghan Catchment, Iran. J. Agric. Sci. Technol. 2012, 14, 1161–1174. [Google Scholar]
- Rahmati, O.; Samani, A.N.; Mahdavi, M.; Pourghasemi, H.R.; Zeinivand, H. Groundwater potential mapping at Kurdistan region of Iran using analytic hierarchy process and GIS. Arab. J. Geosci. 2015, 8, 7059–7071. [Google Scholar] [CrossRef]
- Oh, H.J.; Kim, Y.S.; Choi, J.K.; Park, E.; Lee, S. GIS mapping of regional probabilistic groundwater potential in the area of Pohang City, Korea. J. Hydrol. 2011, 399, 158–172. [Google Scholar] [CrossRef]
- Zabihi, M.; Pourghasemi, H.R.; Pourtaghi, Z.S.; Behzadfar, M. GIS-based multivariate adaptive regression spline and random forest models for groundwater potential mapping in Iran. Environ. Earth Sci. 2016, 75, 665. [Google Scholar] [CrossRef]
- Moghaddam, D.D.; Rezaei, M.; Pourghasemi, H.; Pourtaghie, Z.; Pradhan, B. Groundwater spring potential mapping using bivariate statistical model and GIS in the Taleghan watershed, Iran. Arab. J. Geosci. 2015, 8, 913–929. [Google Scholar] [CrossRef]
- Kumar, U.; Kumar, B.; Mallick, N. Groundwater Prospects Zonation Based on RS and GIS Using Fuzzy Algebra in Khoh River Watershed, Pauri-Garhwal District, Uttarakhand, India. Glob. Perspect. Geogr. 2013, 1, 37–45. [Google Scholar]
- Israil, M.; Singhal, D.C.; Kumar, B.; Rao, M.S.; Verma, K. Groundwater resources evaluation in the Piedmont zone of Himalaya, India, using Isotope and GIS techniques. J. Spat. Hydrol. 2006, 6, 105–119. [Google Scholar]
- Kumar, B.; Kumar, U. Integrated approach using RS and GIS techniques for mapping of ground water prospects in Lower Sanjai Watershed, Jharkhand. Int. J. Geomat. Geosci. 2010, 1, 587–598. [Google Scholar]
- Kumar, A.; Sharma, H.C.; Kumar, S. Planning for replenishing the depleted groundwater in upper Gangetic plains using RS and GIS. Indian J. Soil Conserv. 2011, 39, 195–201. [Google Scholar]
- Thilagavathi, N.; Subramani, T.; Suresh, M.; Karunanidhi, D. Mapping of groundwater potential zones in Salem Chalk Hills, Tamil Nadu, India, using remote sensing and GIS techniques. Environ. Monit. Assess. 2015, 187, 164. [Google Scholar] [CrossRef]
- Jha, M.K.; Bongane, G.M.; Chowdary, V.M.; Cluckie, I.D.; Chen, Y.; Babovic, V.; Konikow, L.; Mynett, A.; Demuth, S.; Savic, D.A. Groundwater potential zoning by remote sensing, GIS and MCDM techniques: A case study of eastern India. In Proceedings of the Symposium JS.4 at the IAHS & IAH Convention, Hyderabad, India, 6–12 September 2009; pp. 432–441. [Google Scholar]
- Ozdemir, A. Using a binary logistic regression method and GIS for evaluating and mapping the groundwater spring potential in the Sultan Mountains (Aksehir, Turkey). J. Hydrol. 2011, 405, 123–136. [Google Scholar] [CrossRef]
- Elbeih, S.F. An overview of integrated remote sensing and GIS for groundwater mapping in Egypt. Ain Shams Eng. J. 2015, 6, 1–15. [Google Scholar] [CrossRef] [Green Version]
- Javed, A.; Wani, M.H. Delineation of groundwater potential zones in Kakund watershed, Eastern Rajasthan, using remote sensing and GIS techniques. J. Geol. Soc. India 2009, 73, 229–236. [Google Scholar] [CrossRef]
- Kumar, T.; Gautam, A.K.; Kumar, T. Appraising the accuracy of GIS-based Multi-criteria decision making technique for delineation of Groundwater potential zones. Water Resour. Manag. 2014, 28, 4449–4466. [Google Scholar] [CrossRef]
- Rahmati, O.; Choubin, B.; Fathabadi, A.; Coulon, F.; Soltani, E.; Shahabi, H.; Mollaefar, E.; Tiefenbacher, J.; Cipullo, S.; Ahmad, B.B.; et al. Predicting uncertainty of machine learning models for modelling nitrate pollution of groundwater using quantile regression and UNEEC methods. Sci. Total Environ. 2019, 688, 855–866. [Google Scholar] [CrossRef] [PubMed]
- Chen, W.; Pradhan, B.; Li, S.; Shahabi, H.; Rizeei, H.M.; Hou, E.; Wang, S. Novel hybrid integration approach of bagging-based fisher’s linear discriminant function for groundwater potential analysis. Nat. Resour. Res. 2019, 28, 1239–1258. [Google Scholar] [CrossRef]
- Miraki, S.; Zanganeh, S.H.; Chapi, K.; Singh, V.P.; Shirzadi, A.; Shahabi, H.; Pham, B.T. Mapping groundwater potential using a novel hybrid intelligence approach. Water Resour. Manag. 2019, 33, 281–302. [Google Scholar] [CrossRef]
- Rahmati, O.; Naghibi, S.A.; Shahabi, H.; Bui, D.T.; Pradhan, B.; Azareh, A.; Rafiei-Sardooi, E.; Samani, A.N.; Melesse, A.M. Groundwater spring potential modelling: Comprising the capability and robustness of three different modeling approaches. J. Hydrol. 2018, 565, 248–261. [Google Scholar] [CrossRef]
- Machiwal, D.; Jha, M.K.; Mal, B.C. Assessment of groundwater potential in a semi-arid region of India using remote sensing, GIS and MCDM techniques. Water Resour. Manag. 2011, 25, 1359–1386. [Google Scholar] [CrossRef]
- Adiat, K.; Nawawi, M.; Abdullah, K. Assessing the accuracy of GIS-based elementary multi criteria decision analysis as a spatial prediction tool–A case of predicting potential zones of sustainable groundwater resources. J. Hydrol. 2012, 440, 75–89. [Google Scholar] [CrossRef]
- Shekhar, S.; Pandey, A.C. Delineation of groundwater potential zone in hard rock terrain of India using remote sensing, geographical information system (GIS) and analytic hierarchy process (AHP) techniques. Geocarto Int. 2015, 30, 402–421. [Google Scholar] [CrossRef]
- Chowdhury, A.; Jha, M.; Chowdary, V.; Mal, B. Integrated remote sensing and GIS-based approach for assessing groundwater potential in West Medinipur district, West Bengal, India. Int. J. Remote Sens. 2009, 30, 231–250. [Google Scholar] [CrossRef]
- Chenini, I.; Mammou, A.B. Groundwater recharge study in arid region: An approach using GIS techniques and numerical modeling. Comput. Geosci. 2010, 36, 801–817. [Google Scholar] [CrossRef]
- Gupta, M.; Srivastava, P.K. Integrating GIS and remote sensing for identification of groundwater potential zones in the hilly terrain of Pavagarh, Gujarat, India. Water Int. 2010, 35, 233–245. [Google Scholar] [CrossRef]
- Murthy, K.; Mamo, A.G. Multi-criteria decision evaluation in groundwater zones identification in Moyale-Teltele subbasin, South Ethiopia. Int. J. Remote Sens. 2009, 30, 2729–2740. [Google Scholar] [CrossRef]
- Lee, S.; Kim, Y.S.; Oh, H.J. Application of a weights-of-evidence method and GIS to regional groundwater productivity potential mapping. J. Environ. Manag. 2012, 96, 91–105. [Google Scholar] [CrossRef] [PubMed]
- Corsini, A.; Cervi, F.; Ronchetti, F. Weight of evidence and artificial neural networks for potential groundwater spring mapping: An application to the Mt. Modino area (Northern Apennines, Italy). Geomorphology 2009, 111, 79–87. [Google Scholar] [CrossRef]
- Al-Abadi, A.M. Groundwater potential mapping at northeastern Wasit and Missan governorates, Iraq using a data-driven weights of evidence technique in framework of GIS. Environ. Earth Sci. 2015, 74, 1109–1124. [Google Scholar] [CrossRef]
- Mogaji, K.; Omosuyi, G.; Adelusi, A.; Lim, H. Application of GIS-Based Evidential Belief Function Model to Regional Groundwater Recharge Potential Zones Mapping in Hardrock Geologic Terrain. Environ. Process. 2016, 3, 93–123. [Google Scholar] [CrossRef]
- Nampak, H.; Pradhan, B.; Manap, M.A. Application of GIS based data driven evidential belief function model to predict groundwater potential zonation. J. Hydrol. 2014, 513, 283–300. [Google Scholar] [CrossRef]
- Naghibi, S.A.; Pourghasemi, H.R.; Pourtaghi, Z.S.; Rezaei, A. Groundwater qanat potential mapping using frequency ratio and Shannon’s entropy models in the Moghan watershed, Iran. Earth Sci. Inform. 2015, 8, 171–186. [Google Scholar] [CrossRef]
- Tahmassebipoor, N.; Rahmati, O.; Noormohamadi, F.; Lee, S. Spatial analysis of groundwater potential using weights-of-evidence and evidential belief function models and remote sensing. Arab. J. Geosci. 2016, 9, 79. [Google Scholar] [CrossRef]
- Kim, K.D.; Lee, S.; Oh, H.J.; Choi, J.K.; Won, J.S. Assessment of ground subsidence hazard near an abandoned underground coal mine using GIS. Environ. Geol. 2006, 50, 1183–1191. [Google Scholar] [CrossRef]
- Aguilera, P.A.; Fernández, A.; Ropero, R.F.; Molina, L. Groundwater quality assessment using data clustering based on hybrid Bayesian networks. Stoch. Environ. Res. Risk Assess. 2013, 27, 435–447. [Google Scholar] [CrossRef]
- Duan, H.; Deng, Z.; Deng, F.; Wang, D. Assessment of Groundwater Potential Based on Multicriteria Decision Making Model and Decision Tree Algorithms. Math. Probl. Eng. 2016, 16, 1–11. [Google Scholar] [CrossRef]
- Lee, S.; Lee, C.W. Application of Decision-Tree Model to Groundwater Productivity-Potential Mapping. Sustainability 2015, 7, 13416–13432. [Google Scholar] [CrossRef] [Green Version]
- Cracknell, M.J.; Reading, A.M. Geological mapping using remote sensing data: A comparison of five machine learning algorithms, their response to variations in the spatial distribution of training data and the use of explicit spatial information. Comput. Geosci. 2014, 63, 22–33. [Google Scholar] [CrossRef] [Green Version]
- Papacharalampous, G.; Tyralis, H.; Koutsoyiannis, D. Comparison of stochastic and machine learning methods for multi-step ahead forecasting of hydrological processes. Stoch. Environ. Res. Risk Assess. 2019, 33, 481–514. [Google Scholar] [CrossRef]
- Tripathi, S.; Srinivas, V.; Nanjundiah, R.S. Downscaling of precipitation for climate change scenarios: A support vector machine approach. J. Hydrol. 2006, 330, 621–640. [Google Scholar] [CrossRef]
- Emamgholizadeh, S.; Bateni, S.M.; Nielson, J.R. Evaluation of different strategies for management of reservoir sedimentation in semi-arid regions: A case study (Dez Reservoir). Lake Reserv. Manag. 2018, 34, 270–282. [Google Scholar] [CrossRef]
- Kisi, O.; Shiri, J. River suspended sediment estimation by climatic variables implication: Comparative study among soft computing techniques. Comput. Geosci. 2012, 43, 73–82. [Google Scholar] [CrossRef]
- Liu, B.; Xu, M.; Henderson, M.; Gong, W. A spatial analysis of pan evaporation trends in China, 1955–2000. J. Geophys. Res. Atmos. 2004, 109, 1–9. [Google Scholar] [CrossRef]
- Izadifar, Z.; Elshorbagy, A. Prediction of hourly actual evapotranspiration using neural networks, genetic programming, and statistical models. Hydrol. Process. 2010, 24, 3413–3425. [Google Scholar] [CrossRef]
- Rezaie-Balf, M.; Kisi, O.; Chua, L.H. Application of ensemble empirical mode decomposition based on machine learning methodologies in forecasting monthly pan evaporation. Hydrol. Res. 2018, 50, 498–516. [Google Scholar] [CrossRef]
- Jadhav, M.S.; Khare, K.C.; Warke, A.S. Water Quality Prediction of Gangapur Reservoir (India) Using LS-SVM and Genetic Programming. Lakes Reserv. Res. Manag. 2015, 20, 275–284. [Google Scholar] [CrossRef]
- Nwachukwu, A.; Jeong, H.; Pyrcz, M.; Lake, L.W. Fast evaluation of well placements in heterogeneous reservoir models using machine learning. J. Pet. Sci. Eng. 2018, 163, 463–475. [Google Scholar] [CrossRef]
- Chapi, K.; Singh, V.P.; Shirzadi, A.; Shahabi, H.; Bui, D.T.; Pham, B.T.; Khosravi, K. A novel hybrid artificial intelligence approach for flood susceptibility assessment. Environ. Model. Softw. 2017, 95, 229–245. [Google Scholar] [CrossRef]
- Wang, Y.; Hong, H.; Chen, W.; Li, S.; Panahi, M.; Khosravi, K.; Shirzadi, A.; Shahabi, H.; Panahi, S.; Costache, R. Flood susceptibility mapping in dingnan county (China) using adaptive neuro-fuzzy inference system with biogeography based optimization and imperialistic competitive algorithm. J. Environ. Manag. 2019, 247, 712–729. [Google Scholar] [CrossRef] [PubMed]
- Khosravi, K.; Pham, B.T.; Chapi, K.; Shirzadi, A.; Shahabi, H.; Revhaug, I.; Prakash, I.; Bui, D.T. A comparative assessment of decision trees algorithms for flash flood susceptibility modeling at Haraz watershed, northern Iran. Sci. Total Environ. 2018, 627, 744–755. [Google Scholar] [CrossRef] [PubMed]
- Ahmadlou, M.; Karimi, M.; Alizadeh, S.; Shirzadi, A.; Parvinnejhad, D.; Shahabi, H.; Panahi, M. Flood susceptibility assessment using integration of adaptive network-based fuzzy inference system (ANFIS) and biogeography-based optimization (BBO) and BAT algorithms (BA). Geocarto Int. 2019, 34, 1252–1272. [Google Scholar] [CrossRef]
- Shafizadeh-Moghadam, H.; Valavi, R.; Shahabi, H.; Chapi, K.; Shirzadi, A. Novel forecasting approaches using combination of machine learning and statistical models for flood susceptibility mapping. J. Environ. Manag. 2018, 217, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Thüring, T.; Schoch, M.; van Herwijnen, A.; Schweizer, J. Robust snow avalanche detection using supervised machine learning with infrasonic sensor arrays. Cold Reg. Sci. Technol. 2015, 111, 60–66. [Google Scholar] [CrossRef]
- Sahoo, S.; Russo, T.A.; Elliott, J.; Foster, I. Machine learning algorithms for modeling groundwater level changes in agricultural regions of the US. Water Resour. Res. 2017, 53, 3878–3895. [Google Scholar] [CrossRef]
- Kashif Gill, M.; Kemblowski, M.W.; McKee, M. Soil moisture data assimilation using support vector machines and ensemble Kalman filter 1. JAWRA J. Am. Water Resour. Assoc. 2007, 43, 1004–1015. [Google Scholar] [CrossRef]
- Su, F.; Wu, J.; He, S. Set pair analysis-Markov chain model for groundwater quality assessment and prediction: A case study of Xi’an city, China. Hum. Ecol. Risk Assess. Int. J. 2019, 25, 158–175. [Google Scholar] [CrossRef]
- Khosravi, K.; Shahabi, H.; Pham, B.T.; Adamowski, J.; Shirzadi, A.; Pradhan, B.; Dou, J.; Ly, H.B.; Gróf, G.; Ho, H.L. A comparative assessment of flood susceptibility modeling using Multi-Criteria Decision-Making Analysis and Machine Learning Methods. J. Hydrol. 2019, 573, 311–323. [Google Scholar] [CrossRef]
- Chen, W.; Hong, H.; Li, S.; Shahabi, H.; Wang, Y.; Wang, X.; Ahmad, B.B. Flood susceptibility modelling using novel hybrid approach of reduced-error pruning trees with bagging and random subspace ensembles. J. Hydrol. 2019, 575, 864–873. [Google Scholar] [CrossRef]
- Tien Bui, D.; Khosravi, K.; Shahabi, H.; Daggupati, P.; Adamowski, J.F.; Melesse, A.M.; Thai Pham, B.; Pourghasemi, H.R.; Mahmoudi, M.; Bahrami, S. Flood spatial modeling in northern Iran using remote sensing and gis: A comparison between evidential belief functions and its ensemble with a multivariate logistic regression model. Remote Sens. 2019, 11, 1589. [Google Scholar] [CrossRef]
- Bui, D.T.; Panahi, M.; Shahabi, H.; Singh, V.P.; Shirzadi, A.; Chapi, K.; Khosravi, K.; Chen, W.; Panahi, S.; Li, S. Novel hybrid evolutionary algorithms for spatial prediction of floods. Sci. Rep. 2018, 8, 15364. [Google Scholar] [CrossRef] [PubMed]
- Tien Bui, D.; Khosravi, K.; Li, S.; Shahabi, H.; Panahi, M.; Singh, V.; Chapi, K.; Shirzadi, A.; Panahi, S.; Chen, W. New hybrids of anfis with several optimization algorithms for flood susceptibility modeling. Water 2018, 10, 1210. [Google Scholar] [CrossRef]
- Jaafari, A.; Zenner, E.K.; Panahi, M.; Shahabi, H. Hybrid artificial intelligence models based on a neuro-fuzzy system and metaheuristic optimization algorithms for spatial prediction of wildfire probability. Agric. For. Meteorol. 2019, 266, 198–207. [Google Scholar] [CrossRef]
- Taheri, K.; Shahabi, H.; Chapi, K.; Shirzadi, A.; Gutiérrez, F.; Khosravi, K. Sinkhole susceptibility mapping: A comparison between Bayes-based machine learning algorithms. Land Degrad. Dev. 2019, 30, 730–745. [Google Scholar] [CrossRef]
- Roodposhti, M.S.; Safarrad, T.; Shahabi, H. Drought sensitivity mapping using two one-class support vector machine algorithms. Atmos. Res. 2017, 193, 73–82. [Google Scholar] [CrossRef]
- Lee, S.; Panahi, M.; Pourghasemi, H.R.; Shahabi, H.; Alizadeh, M.; Shirzadi, A.; Khosravi, K.; Melesse, A.M.; Yekrangnia, M.; Rezaie, F. Sevucas: A Novel GIS-Based Machine Learning Software for Seismic Vulnerability Assessment. Appl. Sci. 2019, 9, 3495. [Google Scholar] [CrossRef]
- Alizadeh, M.; Alizadeh, E.; Asadollahpour Kotenaee, S.; Shahabi, H.; Beiranvand Pour, A.; Panahi, M.; Bin Ahmad, B.; Saro, L. Social vulnerability assessment using artificial neural network (ANN) model for earthquake hazard in Tabriz city, Iran. Sustainability 2018, 10, 3376. [Google Scholar] [CrossRef]
- Azareh, A.; Rahmati, O.; Rafiei-Sardooi, E.; Sankey, J.B.; Lee, S.; Shahabi, H.; Ahmad, B.B. Modelling gully-erosion susceptibility in a semi-arid region, Iran: Investigation of applicability of certainty factor and maximum entropy models. Sci. Total Environ. 2019, 655, 684–696. [Google Scholar] [CrossRef] [PubMed]
- Tien Bui, D.; Shirzadi, A.; Shahabi, H.; Chapi, K.; Omidavr, E.; Pham, B.T.; Talebpour Asl, D.; Khaledian, H.; Pradhan, B.; Panahi, M. A Novel Ensemble Artificial Intelligence Approach for Gully Erosion Mapping in a Semi-Arid Watershed (Iran). Sensors 2019, 19, 2444. [Google Scholar] [CrossRef] [PubMed]
- Tien Bui, D.; Shahabi, H.; Shirzadi, A.; Chapi, K.; Pradhan, B.; Chen, W.; Khosravi, K.; Panahi, M.; Bin Ahmad, B.; Saro, L. Land subsidence susceptibility mapping in south korea using machine learning algorithms. Sensors 2018, 18, 2464. [Google Scholar] [CrossRef] [PubMed]
- Tien Bui, D.; Shahabi, H.; Shirzadi, A.; Chapi, K.; Alizadeh, M.; Chen, W.; Mohammadi, A.; Ahmad, B.; Panahi, M.; Hong, H. Landslide detection and susceptibility mapping by airsar data using support vector machine and index of entropy models in cameron highlands, malaysia. Remote Sens. 2018, 10, 1527. [Google Scholar] [CrossRef]
- Chen, W.; Peng, J.; Hong, H.; Shahabi, H.; Pradhan, B.; Liu, J.; Zhu, A.X.; Pei, X.; Duan, Z. Landslide susceptibility modelling using GIS-based machine learning techniques for Chongren County, Jiangxi Province, China. Sci. Total Environ. 2018, 626, 1121–1135. [Google Scholar] [CrossRef] [PubMed]
- Pham, B.T.; Prakash, I.; Singh, S.K.; Shirzadi, A.; Shahabi, H.; Bui, D.T. Landslide susceptibility modeling using Reduced Error Pruning Trees and different ensemble techniques: Hybrid machine learning approaches. Catena 2019, 175, 203–218. [Google Scholar] [CrossRef]
- Shirzadi, A.; Bui, D.T.; Pham, B.T.; Solaimani, K.; Chapi, K.; Kavian, A.; Shahabi, H.; Revhaug, I. Shallow landslide susceptibility assessment using a novel hybrid intelligence approach. Environ. Earth Sci. 2017, 76, 60. [Google Scholar] [CrossRef]
- Pham, B.T.; Prakash, I.; Dou, J.; Singh, S.K.; Trinh, P.T.; Tran, H.T.; Le, T.M.; Van Phong, T.; Khoi, D.K.; Shirzadi, A. A novel hybrid approach of landslide susceptibility modelling using rotation forest ensemble and different base classifiers. Geocarto Int. 2019, 35, 1–25. [Google Scholar] [CrossRef]
- Pradhan, B. A comparative study on the predictive ability of the decision tree, support vector machine and neuro-fuzzy models in landslide susceptibility mapping using GIS. Comput. Geosci. 2013, 51, 350–365. [Google Scholar] [CrossRef]
- Chen, W.; Shahabi, H.; Shirzadi, A.; Hong, H.; Akgun, A.; Tian, Y.; Liu, J.; Zhu, A.X.; Li, S. Novel hybrid artificial intelligence approach of bivariate statistical-methods-based kernel logistic regression classifier for landslide susceptibility modeling. Bull. Eng. Geol. Environ. 2019, 78, 4397–4419. [Google Scholar] [CrossRef]
- He, Q.; Shahabi, H.; Shirzadi, A.; Li, S.; Chen, W.; Wang, N.; Chai, H.; Bian, H.; Ma, J.; Chen, Y. Landslide spatial modelling using novel bivariate statistical based Naïve Bayes, RBF Classifier, and RBF Network machine learning algorithms. Sci. Total Environ. 2019, 663, 1–15. [Google Scholar] [CrossRef] [PubMed]
- Jaafari, A.; Panahi, M.; Pham, B.T.; Shahabi, H.; Bui, D.T.; Rezaie, F.; Lee, S. Meta optimization of an adaptive neuro-fuzzy inference system with grey wolf optimizer and biogeography-based optimization algorithms for spatial prediction of landslide susceptibility. Catena 2019, 175, 430–445. [Google Scholar] [CrossRef]
- Hong, H.; Shahabi, H.; Shirzadi, A.; Chen, W.; Chapi, K.; Ahmad, B.B.; Roodposhti, M.S.; Hesar, A.Y.; Tian, Y.; Bui, D.T. Landslide susceptibility assessment at the Wuning area, China: A comparison between multi-criteria decision making, bivariate statistical and machine learning methods. Nat. Hazards 2019, 96, 173–212. [Google Scholar] [CrossRef]
- Shafizadeh-Moghadam, H.; Minaei, M.; Shahabi, H.; Hagenauer, J. Big data in Geohazard; pattern mining and large scale analysis of landslides in Iran. Earth Sci. Inform. 2019, 12, 1–17. [Google Scholar] [CrossRef]
- Nguyen, V.V.; Pham, B.T.; Vu, B.T.; Prakash, I.; Jha, S.; Shahabi, H.; Shirzadi, A.; Ba, D.N.; Kumar, R.; Chatterjee, J.M. Hybrid machine learning approaches for landslide susceptibility modeling. Forests 2019, 10, 157. [Google Scholar] [CrossRef]
- Pham, B.T.; Shirzadi, A.; Shahabi, H.; Omidvar, E.; Singh, S.K.; Sahana, M.; Asl, D.T.; Ahmad, B.B.; Quoc, N.K.; Lee, S. Landslide Susceptibility Assessment by Novel Hybrid Machine Learning Algorithms. Sustainability 2019, 11, 4386. [Google Scholar] [CrossRef]
- Nguyen, P.T.; Tuyen, T.T.; Shirzadi, A.; Pham, B.T.; Shahabi, H.; Omidvar, E.; Amini, A.; Entezami, H.; Prakash, I.; Phong, T.V. Development of a Novel Hybrid Intelligence Approach for Landslide Spatial Prediction. Appl. Sci. 2019, 9, 2824. [Google Scholar] [CrossRef]
- Tien Bui, D.; Shahabi, H.; Omidvar, E.; Shirzadi, A.; Geertsema, M.; Clague, J.J.; Khosravi, K.; Pradhan, B.; Pham, B.T.; Chapi, K. Shallow landslide prediction using a novel hybrid functional machine learning algorithm. Remote Sens. 2019, 11, 931. [Google Scholar] [CrossRef]
- Tien Bui, D.; Shirzadi, A.; Shahabi, H.; Geertsema, M.; Omidvar, E.; Clague, J.J.; Thai Pham, B.; Dou, J.; Talebpour Asl, D.; Bin Ahmad, B. New Ensemble Models for Shallow Landslide Susceptibility Modeling in a Semi-Arid Watershed. Forests 2019, 10, 743. [Google Scholar] [CrossRef]
- Chen, W.; Zhao, X.; Shahabi, H.; Shirzadi, A.; Khosravi, K.; Chai, H.; Zhang, S.; Zhang, L.; Ma, J.; Chen, Y. Spatial prediction of landslide susceptibility by combining evidential belief function, logistic regression and logistic model tree. Geocarto Int. 2019, 34, 1–25. [Google Scholar] [CrossRef]
- Shirzadi, A.; Solaimani, K.; Roshan, M.H.; Kavian, A.; Chapi, K.; Shahabi, H.; Keesstra, S.; Ahmad, B.B.; Bui, D.T. Uncertainties of prediction accuracy in shallow landslide modeling: Sample size and raster resolution. Catena 2019, 178, 172–188. [Google Scholar] [CrossRef]
- Tien Bui, D.; Shahabi, H.; Shirzadi, A.; Chapi, K.; Hoang, N.D.; Pham, B.; Bui, Q.T.; Tran, C.T.; Panahi, M.; Bin Ahamd, B. A novel integrated approach of relevance vector machine optimized by imperialist competitive algorithm for spatial modeling of shallow landslides. Remote Sens. 2018, 10, 1538. [Google Scholar] [CrossRef]
- Chen, W.; Zhang, S.; Li, R.; Shahabi, H. Performance evaluation of the GIS-based data mining techniques of best-first decision tree, random forest, and naïve Bayes tree for landslide susceptibility modeling. Sci. Total Environ. 2018, 644, 1006–1018. [Google Scholar] [CrossRef] [PubMed]
- Chen, W.; Shahabi, H.; Zhang, S.; Khosravi, K.; Shirzadi, A.; Chapi, K.; Pham, B.; Zhang, T.; Zhang, L.; Chai, H. Landslide susceptibility modeling based on gis and novel bagging-based kernel logistic regression. Appl. Sci. 2018, 8, 2540. [Google Scholar] [CrossRef]
- Zhang, T.; Han, L.; Chen, W.; Shahabi, H. Hybrid integration approach of entropy with logistic regression and support vector machine for landslide susceptibility modeling. Entropy 2018, 20, 884. [Google Scholar] [CrossRef]
- Abedini, M.; Ghasemian, B.; Shirzadi, A.; Shahabi, H.; Chapi, K.; Pham, B.T.; Bin Ahmad, B.; Tien Bui, D. A novel hybrid approach of bayesian logistic regression and its ensembles for landslide susceptibility assessment. Geocarto Int. 2018, 28, 1–31. [Google Scholar] [CrossRef]
- Chen, W.; Xie, X.; Peng, J.; Shahabi, H.; Hong, H.; Bui, D.T.; Duan, Z.; Li, S.; Zhu, A.X. GIS-based landslide susceptibility evaluation using a novel hybrid integration approach of bivariate statistical based random forest method. Catena 2018, 164, 135–149. [Google Scholar] [CrossRef]
- Chen, W.; Shirzadi, A.; Shahabi, H.; Ahmad, B.B.; Zhang, S.; Hong, H.; Zhang, N. A novel hybrid artificial intelligence approach based on the rotation forest ensemble and naïve Bayes tree classifiers for a landslide susceptibility assessment in Langao County, China. Geomat. Nat. Hazards Risk 2017, 8, 1955–1977. [Google Scholar]
- Hong, H.; Liu, J.; Zhu, A.X.; Shahabi, H.; Pham, B.T.; Chen, W.; Pradhan, B.; Bui, D.T. A novel hybrid integration model using support vector machines and random subspace for weather-triggered landslide susceptibility assessment in the Wuning area (China). Environ. Earth Sci. 2017, 76, 652. [Google Scholar] [CrossRef]
- Shadman Roodposhti, M.; Aryal, J.; Shahabi, H.; Safarrad, T. Fuzzy shannon entropy: A hybrid GIS-based landslide susceptibility mapping method. Entropy 2016, 18, 343. [Google Scholar] [CrossRef]
- Shahabi, H.; Hashim, M.; Ahmad, B.B. Remote sensing and GIS-based landslide susceptibility mapping using frequency ratio, logistic regression, and fuzzy logic methods at the central Zab basin, Iran. Environ. Earth Sci. 2015, 73, 8647–8668. [Google Scholar] [CrossRef]
- Shahabi, H.; Khezri, S.; Ahmad, B.B.; Hashim, M. Landslide susceptibility mapping at central Zab basin, Iran: A comparison between analytical hierarchy process, frequency ratio and logistic regression models. Catena 2014, 115, 55–70. [Google Scholar] [CrossRef]
- Darvishan, A.; Sadeghi, S.; Gholami, L. Efficacy of Time-Area Method in simulating temporal variation of sediment yield in Chehelgazi watershed, Iran. Ann. Wars. Univ. Life Sci. SGGW Land Reclam. 2010, 42, 51–60. [Google Scholar] [CrossRef]
- Chen, W.; Panahi, M.; Khosravi, K.; Pourghasemi, H.R.; Rezaie, F.; Parvinnezhad, D. Spatial prediction of groundwater potentiality using anfis ensembled with teaching-learning-based and biogeography-based optimization. J. Hydrol. 2019, 572, 435–448. [Google Scholar] [CrossRef]
- Naghibi, S.A.; Pourghasemi, H.R.; Abbaspour, K. A comparison between ten advanced and soft computing models for groundwater qanat potential assessment in Iran using R and GIS. Theor. Appl. Climatol. 2018, 131, 967–984. [Google Scholar] [CrossRef]
- Al Saud, M. Mapping potential areas for groundwater storage in Wadi Aurnah Basin, western Arabian Peninsula, using remote sensing and geographic information system techniques. Hydrogeol. J. 2010, 18, 1481–1495. [Google Scholar] [CrossRef]
- Ettazarini, S. Groundwater potentiality index: A strategically conceived tool for water research in fractured aquifers. Environ. Geol. 2007, 52, 477–487. [Google Scholar] [CrossRef]
- Oikonomidis, D.; Dimogianni, S.; Kazakis, N.; Voudouris, K. A GIS/Remote Sensing-based methodology for groundwater potentiality assessment in Tirnavos area, Greece. J. Hydrol. 2015, 525, 197–208. [Google Scholar] [CrossRef]
- Marr, J.W. Ecosystems of the East Slope of the Front Range in Colorado; University of Colorado Studies, Series in Biology Number 8; University of Colorado Press: Boulder, CO, USA, 1961. [Google Scholar]
- Broxton, P.D.; Troch, P.A.; Lyon, S.W. On the role of aspect to quantify water transit times in small mountainous catchments. Water Resour. Res. 2009, 45, 1–15. [Google Scholar] [CrossRef]
- Birkeland, P.; Shroba, R.; Burns, S.; Price, A.; Tonkin, P. Integrating soils and geomorphology in mountains—an example from the Front Range of Colorado. Geomorphology 2003, 55, 329–344. [Google Scholar] [CrossRef]
- Casanova, M.; Messing, I.; Joel, A. Influence of aspect and slope gradient on hydraulic conductivity measured by tension infiltrometer. Hydrol. Process. 2000, 14, 155–164. [Google Scholar] [CrossRef]
- Geroy, I.; Gribb, M.; Marshall, H.P.; Chandler, D.G.; Benner, S.G.; McNamara, J.P. Aspect influences on soil water retention and storage. Hydrol. Process. 2011, 25, 3836–3842. [Google Scholar] [CrossRef]
- Veblen, T.T.; Lorenz, D.C. The Colorado Front Range: A Century of Ecological Change; The University of Utah Press: Salt Lake City, UT, USA, 1991. [Google Scholar]
- Pourghasemi, H.R.; Beheshtirad, M. Assessment of a data-driven evidential belief function model and GIS for groundwater potential mapping in the Koohrang Watershed, Iran. Geocarto Int. 2015, 30, 662–685. [Google Scholar] [CrossRef]
- Naghibi, S.A.; Pourghasemi, H.R. A comparative assessment between three machine learning models and their performance comparison by bivariate and multivariate statistical methods in groundwater potential mapping. Water Resour. Manag. 2015, 29, 5217–5236. [Google Scholar] [CrossRef]
- Pradhan, A.M.S.; Kim, Y.T. Relative effect method of landslide susceptibility zonation in weathered granite soil: A case study in Deokjeok-ri Creek, South Korea. Nat. Hazards 2014, 72, 1189–1217. [Google Scholar] [CrossRef]
- Devkota, K.C.; Regmi, A.D.; Pourghasemi, H.R.; Yoshida, K.; Pradhan, B.; Ryu, I.C.; Dhital, M.R.; Althuwaynee, O.F. Landslide susceptibility mapping using certainty factor, index of entropy and logistic regression models in GIS and their comparison at Mugling–Narayanghat road section in Nepal Himalaya. Nat. Hazards 2013, 65, 135–165. [Google Scholar] [CrossRef]
- Magesh, N.; Chandrasekar, N.; Soundranayagam, J.P. Delineation of groundwater potential zones in Theni district, Tamil Nadu, using remote sensing, GIS and MIF techniques. Geosci. Front. 2012, 3, 189–196. [Google Scholar] [CrossRef] [Green Version]
- Manap, M.A.; Nampak, H.; Pradhan, B.; Lee, S.; Sulaiman, W.N.A.; Ramli, M.F. Application of probabilistic-based frequency ratio model in groundwater potential mapping using remote sensing data and GIS. Arab. J. Geosci. 2014, 7, 711–724. [Google Scholar] [CrossRef]
- Moore, I.D.; Wilson, J.P. Length-slope factors for the Revised Universal Soil Loss Equation: Simplified method of estimation. J. Soil Water Conserv. 1992, 47, 423–428. [Google Scholar]
- Naghibi, S.A.; Pourghasemi, H.R.; Dixon, B. GIS-based groundwater potential mapping using boosted regression tree, classification and regression tree, and random forest machine learning models in Iran. Environ. Monit. Assess. 2016, 188, 44. [Google Scholar] [CrossRef] [PubMed]
- Moore, I.D.; Grayson, R.; Ladson, A. Digital terrain modelling: A review of hydrological, geomorphological, and biological applications. Hydrol. Process. 1991, 5, 3–30. [Google Scholar] [CrossRef]
- Chen, W.; Tsangaratos, P.; Ilia, I.; Duan, Z.; Chen, X. Groundwater spring potential mapping using population-based evolutionary algorithms and data mining methods. Sci. Total Environ. 2019, 684, 31–49. [Google Scholar] [CrossRef] [PubMed]
- Dinesh Kumar, P.; Gopinath, G.; Seralathan, P. Application of remote sensing and GIS for the demarcation of groundwater potential zones of a river basin in Kerala, southwest coast of India. Int. J. Remote Sens. 2007, 28, 5583–5601. [Google Scholar] [CrossRef]
- Chowdhury, A.; Jha, M.K.; Chowdary, V. Delineation of groundwater recharge zones and identification of artificial recharge sites in West Medinipur district, West Bengal, using RS, GIS and MCDM techniques. Environ. Earth Sci. 2010, 59, 1209. [Google Scholar] [CrossRef]
- Shaban, A.; Khawlie, M.; Abdallah, C. Use of remote sensing and GIS to determine recharge potential zones: The case of Occidental Lebanon. Hydrogeol. J. 2006, 14, 433–443. [Google Scholar] [CrossRef]
- Gutirrez, P.A.; Fernndez, J.C.; Herv, C.; Lpezgranados, F.; Juradoexpsito, M.; Peabarrag, J.M. Feature Selection for Hybrid Neuro-Logistic Regression Applied to Classification of Remote Sensed Data. In Proceedings of the International Conference on Hybrid Intelligent Systems, Barcelona, Spain, 10–12 September 2008; pp. 625–630. [Google Scholar]
- Chen, W.; Pourghasemi, H.R.; Zhao, Z. A GIS-based comparative study of Dempster-Shafer, logistic regression and artificial neural network models for landslide susceptibility mapping. Geocarto Int. 2017, 32, 367–385. [Google Scholar] [CrossRef]
- Park, H.A. An introduction to logistic regression: From basic concepts to interpretation with particular attention to nursing domain. J. Korean Acad. Nurs. 2013, 43, 154–164. [Google Scholar] [CrossRef]
- Tien Bui, D.; Tuan, T.A.; Klempe, H.; Pradhan, B.; Revhaug, I. Spatial prediction models for shallow landslide hazards: A comparative assessment of the efficacy of support vector machines, artificial neural networks, kernel logistic regression, and logistic model tree. Landslides 2016, 13, 361–378. [Google Scholar] [CrossRef]
- Sumner, M.; Frank, E.; Hall, M. Speeding up logistic model tree induction. J. Min. Sci. 2005, 45, 227–234. [Google Scholar]
- Breiman, L. Classification and Regression Trees; Routledge: New York, NY, USA, 2017. [Google Scholar]
- Wang, Y.; Choi, I.C.; Liu, H. Generalized Ensemble Model for Document Ranking in Information Retrieval. IEEE Trans. Knowl. Data Eng. 2015, 41, 367–395. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Chen, W.; Wang, J.; Xie, X.; Hong, H.; Trung, N.V.; Bui, D.T.; Wang, G.; Li, X. Spatial prediction of landslide susceptibility using integrated frequency ratio with entropy and support vector machines by different kernel functions. Environ. Earth Sci. 2016, 75, 1344. [Google Scholar] [CrossRef]
- Chen, W.; Pourghasemi, H.R.; Kornejady, A.; Zhang, N. Landslide spatial modeling: Introducing new ensembles of ANN, MaxEnt, and SVM machine learning techniques. Geoderma 2017, 305, 314–327. [Google Scholar] [CrossRef]
- Freund, Y.; Mason, L. The alternating decision tree learning algorithm. Icml 1999, 99, 124–133. [Google Scholar]
- Pham, B.T.; Bui, D.T.; Dholakia, M.; Prakash, I.; Pham, H.V. A comparative study of least square support vector machines and multiclass alternating decision trees for spatial prediction of rainfall-induced landslides in a tropical cyclones area. Geotech. Geol. Eng. 2016, 34, 1807–1824. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Cutler, D.R.; Edwards, T.C., Jr.; Beard, K.H.; Cutler, A.; Hess, K.T.; Gibson, J.; Lawler, J.J. Random forests for classification in ecology. Ecology 2007, 88, 2783–2792. [Google Scholar] [CrossRef]
- Wiesmeier, M.; Barthold, F.; Blank, B.; Kögel-Knabner, I. Digital mapping of soil organic matter stocks using Random Forest modeling in a semi-arid steppe ecosystem. Plant Soil 2011, 340, 7–24. [Google Scholar] [CrossRef]
- Liaw, A.; Wiener, M. Classification and regression by randomForest. R News 2002, 2, 18–22. [Google Scholar]
- Freund, Y.; Schapire, R.E. A Decision-Theoretic Generalization of On-Line Learning and an Application to Boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef] [Green Version]
- Tien Bui, D.; Ho, T.C.; Pradhan, B.; Pham, B.T.; Nhu, V.H.; Revhaug, I. GIS-based modeling of rainfall-induced landslides using data mining-based functional trees classifier with AdaBoost, Bagging, and MultiBoost ensemble frameworks. Environ. Earth Sci. 2016, 75, 1101. [Google Scholar] [CrossRef]
- Beguería, S. Validation and evaluation of predictive models in hazard assessment and risk management. Nat. Hazards 2006, 37, 315–329. [Google Scholar] [CrossRef]
- Hand, D.J. Measuring classifier performance: A coherent alternative to the area under the ROC curve. Mach. Learn. 2009, 77, 103–123. [Google Scholar] [CrossRef]
- Bennett, N.D.; Croke, B.F.; Guariso, G.; Guillaume, J.H.; Hamilton, S.H.; Jakeman, A.J.; Marsili-Libelli, S.; Newham, L.T.; Norton, J.P.; Perrin, C. Characterising performance of environmental models. Environ. Model. Softw. 2013, 40, 1–20. [Google Scholar] [CrossRef]
- Pham, B.T.; Bui, D.T.; Prakash, I.; Dholakia, M. Hybrid integration of Multilayer Perceptron Neural Networks and machine learning ensembles for landslide susceptibility assessment at Himalayan area (India) using GIS. Catena 2017, 149, 52–63. [Google Scholar] [CrossRef]
- Spackman, K.A. Signal detection theory: Valuable tools for evaluating inductive learning. In Proceedings of the Sixth International Workshop on Machine Learning, Ithaca, NY, USA, 26–27 June 1989; pp. 160–163. [Google Scholar]
- Kononenko, I.; Bratko, I. Information-based evaluation criterion for classifier’s performance. Mach. Learn. 1991, 6, 67–80. [Google Scholar] [CrossRef]
- Pietraszek, T. On the use of ROC analysis for the optimization of abstaining classifiers. Mach. Learn. 2007, 68, 137–169. [Google Scholar] [CrossRef] [Green Version]
- Fawcett, T. An introduction to ROC analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Shahabi, H.; Hashim, M. Landslide susceptibility mapping using GIS-based statistical models and Remote sensing data in tropical environment. Sci. Rep. 2015, 5, 9899. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Vanderlooy, S.; Hüllermeier, E. A critical analysis of variants of the AUC. Mach. Learn. 2008, 72, 247–262. [Google Scholar] [CrossRef] [Green Version]
- Shirzadi, A.; Shahabi, H.; Chapi, K.; Bui, D.T.; Pham, B.T.; Shahedi, K.; Ahmad, B.B. A comparative study between popular statistical and machine learning methods for simulating volume of landslides. Catena 2017, 157, 213–226. [Google Scholar] [CrossRef]
- Bui, D.T.; Pradhan, B.; Revhaug, I.; Nguyen, D.B.; Pham, H.V.; Bui, Q.N. A novel hybrid evidential belief function-based fuzzy logic model in spatial prediction of rainfall-induced shallow landslides in the Lang Son city area (Vietnam). Geomat. Nat. Hazards Risk 2015, 6, 243–271. [Google Scholar] [CrossRef]
- Tehrany, M.S.; Pradhan, B.; Mansor, S.; Ahmad, N. Flood susceptibility assessment using GIS-based support vector machine model with different kernel types. Catena 2015, 125, 91–101. [Google Scholar] [CrossRef]
- Yesilnacar, E.K. The Application of Computational Intelligence to Landslide Susceptibility Mapping in Turkey; Department, 200; University of Melbourne: Melbourne, Australia, 2005. [Google Scholar]
- Naghibi, S.A.; Dashtpagerdi, M.M. Evaluation of four supervised learning methods for groundwater spring potential mapping in Khalkhal region (Iran) using GIS-based features. Hydrogeol. J. 2017, 25, 169–189. [Google Scholar] [CrossRef]
- Chan, J.C.W.; Paelinckx, D. Evaluation of Random Forest and Adaboost tree-based ensemble classification and spectral band selection for ecotope mapping using airborne hyperspectral imagery. Remote Sens. Environ. 2008, 112, 2999–3011. [Google Scholar] [CrossRef]
- Shirzadi, A.; Soliamani, K.; Habibnejhad, M.; Kavian, A.; Chapi, K.; Shahabi, H.; Chen, W.; Khosravi, K.; Thai Pham, B.; Pradhan, B. Novel GIS based machine learning algorithms for shallow landslide susceptibility mapping. Sensors 2018, 18, 3777. [Google Scholar] [CrossRef]
- Liu, X.; Sahli, H.; Meng, Y.; Huang, Q.; Lin, L. Flood inundation mapping from optical satellite images using spatiotemporal context learning and modest AdaBoost. Remote Sens. 2017, 9, 617. [Google Scholar] [CrossRef]
- Al-Abadi, A.M. Mapping flood susceptibility in an arid region of southern Iraq using ensemble machine learning classifiers: A comparative study. Arab. J. Geosci. 2018, 11, 218. [Google Scholar] [CrossRef]
- Bui, D.T.; Ho, T.C.; Revhaug, I.; Pradhan, B.; Nguyen, D.B. Landslide susceptibility mapping along the national road 32 of Vietnam using GIS-based J48 decision tree classifier and its ensembles. In Cartography from Pole to Pole; Springer: Berlin/Heidelberg, Germany, 2014; pp. 303–317. [Google Scholar]
- Pham, B.T.; Shirzadi, A.; Bui, D.T.; Prakash, I.; Dholakia, M. A hybrid machine learning ensemble approach based on a radial basis function neural network and rotation forest for landslide susceptibility modeling: A case study in the Himalayan area, India. Int. J. Sediment Res. 2018, 33, 157–170. [Google Scholar] [CrossRef]
- Chen, W.; Shahabi, H.; Shirzadi, A.; Li, T.; Guo, C.; Hong, H.; Li, W.; Pan, D.; Hui, J.; Ma, M. A novel ensemble approach of bivariate statistical-based logistic model tree classifier for landslide susceptibility assessment. Geocarto Int. 2018, 33, 1398–1420. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Minimum | Maximum | Mean | SD | Variance | |
|---|---|---|---|---|---|
| Q (lit/s) | 0.2 | 10 | 0.5631 | 0.278 | 0.278 |
| T (°C) | 0.3 | 27 | 14.812 | 4.636 | 21.494 |
| EC (µmho/cm) | 0.0 | 627 | 364.688 | 126.576 | 160.216 |
| pH | 0.1 | 8.8 | 7.525 | 2.097 | 4.398 |
| Main Factors | No. | Conditioning Factors | Classes |
|---|---|---|---|
| Topographic | 1 | Slope (o) | (1) 0–10; (2) 10–20; (3) 20–30; (4) 30–40; and (5) >40 |
| 2 | Aspect | (1) Flat; (2) North; (3) Northeast; (4) East; (5) Southeast; (6) South; (7) Southwest; (8) West; and (9) Northwest | |
| 3 | Elevation (m) | (1) <1800; (2) 1800–1900; (3) 1900–2000; (4) 2000–2200; and (5) >2200 | |
| 4 | Curvature | (1) ((−13.5)–(−2.24)); (2) ((−2.24)–(−0.661)); (3) ((−0.661)–(−0.394)); (4) >((−0.394)–(−1.66)); and (5) ((−1.66)–(−13.3)) | |
| 5 | Plan curvature | (1) ((−7.78)–(−1.3)); (2) ((−1.3)–(−0.381)); (3) ((−0.381)–0.339); (4) >(0.339–1.45)); and (5) (1.45–8.91)) | |
| 6 | Profile curvature | (1) ((−7.13)–(−1.46)); (2) ((−1.46)–(−0.450)); (3) ((−0.450)–0.141); (4) >(0.141–0.791)); and (5) (0.791–7.89)) | |
| 7 | SPI | (1) 0–500; (2) 500–1000; (3) 1000–1500; (4) 1500–2000; and (5) 2000–116000 | |
| Hydrological | 8 | TWI | (1) 0.649–3.31; (2) 3.31–4.16; (3) 4.16–6.42; (4) 6.42–8.88; and (5) 8.88–10.9 |
| 9 | STI/LS | (1) 0–3.83; (2) 3.83–8.66; (3) 8.66–13.3; (4) 13.3–18.8; and (5) 18.8–42.5 | |
| 10 | Rainfall (mm/y) | (1) 300–340; (2) 340–360; (3) 360–380; (4) 380–400; (5) 400–440; (6) 440–480; and (7) >480 | |
| 11 | Distance to rivers (m) | (1) 0–100; (2) 100–200; (3) 200–300; (4) 300–400; and (5) >400 | |
| 12 | River density (km/km2) | (1) 0–0.000744; (2) 0.000744–0.00169; (3) 0.00169–0. 00248; (4) 0. 00248–0.00337; and (5) 0.00337–0.00633 | |
| Geological | 13 | Lithology | (1) Alluvial fan and terraces (Qt1 and Qt2); (2) alluvial deposits (Qal); (3) limestone (Kul, Kpf and Kf1); (4) sandstone (Kvsl); (5) shale (Kss); (6) turbidite sequence (Ktsc); (7) conglomerate with intermediate of Sandston (Klt); (8) un-granulated conglomerate with shale and sandstone (Kco); (9) lava and tuff (Kvc and Kv); and (10) coarse-grained gabbro (gb) |
| 14 | Distance to faults (m) | (1) 0–100; (2) 100–200; (3) 200–300; (4) 300–400; and (5) >400 | |
| 15 | Fault density(km/km2) | (1) 0–0.000418; (2) 0.000418–0.00114; (3) 0.00114–0. 00185; (4) 0. 00185–0.00267; and (5) 0.00267–0.00508 | |
| 16 | Permeability | (1) Very low; (2) low; (3) moderate; and (4) high | |
| Land cover | 17 | Land use | (1) Woodland; (2) residential area; (3) barren land; (4) outcrop land; (5) range land; (6) dry farming land; and (7) farming land |
| Predicted | ||||
|---|---|---|---|---|
| (Spring) | (Non-Spring) | Sum | ||
| Observed | (spring) | TP | FN | P |
| (non-spring) | FP | TN | N | |
| AB–ADTree | ADTree | SGD | LMT | LR | SVM | RF | |
|---|---|---|---|---|---|---|---|
| True positive | 344 | 310 | 336 | 324 | 326 | 327 | 332 |
| True negative | 366 | 341 | 316 | 335 | 333 | 332 | 333 |
| False positive | 78 | 103 | 128 | 109 | 111 | 112 | 111 |
| False negative | 100 | 134 | 108 | 120 | 118 | 117 | 112 |
| PPV (%) | 0.815 | 0.751 | 0.724 | 0.748 | 0.746 | 0.745 | 0.749 |
| NPV (%) | 0.785 | 0.718 | 0.745 | 0.736 | 0.738 | 0.739 | 0.748 |
| Sensitivity (%) | 0.775 | 0.698 | 0.757 | 0.730 | 0.734 | 0.736 | 0.748 |
| Specificity (%) | 0.824 | 0.768 | 0.712 | 0.755 | 0.750 | 0.748 | 0.750 |
| Accuracy (%) | 0.800 | 0.733 | 0.734 | 0.742 | 0.742 | 0.742 | 0.751 |
| RMSE | 0.375 | 0.424 | 0.515 | 0.418 | 0.417 | 0.418 | 0.401 |
| AUC | 0.881 | 0.817 | 0.675 | 0.815 | 0.816 | 0.815 | 0.818 |
| AB–ADTree | ADTree | SGD | LMT | LR | SVM | RF | |
|---|---|---|---|---|---|---|---|
| True positive | 145 | 143 | 150 | 146 | 147 | 147 | 147 |
| True negative | 137 | 131 | 130 | 135 | 135 | 134 | 134 |
| False positive | 53 | 59 | 60 | 55 | 55 | 56 | 56 |
| False negative | 45 | 47 | 40 | 44 | 43 | 43 | 43 |
| PPV (%) | 0.732 | 0.708 | 0.714 | 0.726 | 0.728 | 0.724 | 0.724 |
| NPV (%) | 0.753 | 0.736 | 0.765 | 0.754 | 0.758 | 0.757 | 0.757 |
| Sensitivity (%) | 0.763 | 0.753 | 0.789 | 0.768 | 0.774 | 0.774 | 0.774 |
| Specificity (%) | 0.721 | 0.689 | 0.684 | 0.711 | 0.711 | 0.705 | 0.705 |
| Accuracy (%) | 0.742 | 0.721 | 0.737 | 0.739 | 0.742 | 0.739 | 0.739 |
| RMSE | 0.419 | 0.375 | 0.513 | 0.426 | 0.425 | 0.426 | 0.413 |
| AUC | 0.829 | 0.790 | 0.675 | 0.803 | 0.807 | 0.805 | 0.809 |
| GSPM | Mean Ranks | χ2 | Sig. |
|---|---|---|---|
| AB–ADTree | 1.34 | 3390.071 | 0.000 |
| ADTree | 2.27 | ||
| SGD | 5.89 | ||
| LMT | 3.05 | ||
| LR | 3.09 | ||
| SVM | 4.90 | ||
| RF | 3.59 |
| Pair Wise Comparison | Npd | Nnd | z-Value | p-Value | Significance |
|---|---|---|---|---|---|
| AB–ADTree vs. ADTree | 525 | 835 | –20.704 | 0.000 | Yes |
| AB–ADTree vs. SGD | 33 | 854 | –25.320 | 0.000 | Yes |
| AB–ADTree vs. LMT | 102 | 785 | –19.956 | 0.000 | Yes |
| AB–ADTree vs. LR | 63 | 821 | –21.162 | 0.000 | Yes |
| AB–ADTree vs. SVM | 44 | 843 | –24.197 | 0.000 | Yes |
| AB–ADTree vs. RF | 59 | 836 | –13.569 | 0.010 | Yes |
| ADTree vs. SGD | 0 | 887 | –25.800 | 0.000 | Yes |
| ADTree vs. LMT | 361 | 526 | –6.042 | 0.000 | Yes |
| ADTree vs. LR | 309 | 573 | –12.142 | 0.000 | Yes |
| ADTree vs. SVM | 17 | 870 | –25.697 | 0.000 | Yes |
| ADTree vs. RF | 789 | 48 | –23.658 | 0.000 | Yes |
| SGD vs. LMT | 859 | 29 | –25.677 | 0.000 | Yes |
| SGD vs. LR | 887 | 0 | –25.800 | 0.000 | Yes |
| SGD vs. SVM | 855 | 32 | –25.558 | 0.000 | Yes |
| SGD vs. RF | 815 | 26 | –22.348 | 0.020 | Yes |
| LMT vs. LR | 428 | 459 | –2.067 | 0.039 | Yes |
| LMT vs. SVM | 55 | 833 | –25.027 | 0.000 | Yes |
| LMT vs. RF | 659 | 29 | –20.123 | 0.000 | Yes |
| LR vs. SVM | 886 | 0 | –25.785 | 0.000 | Yes |
| LR vs. RF | 826 | 15 | –18.236 | 0.031 | Yes |
| SVM vs. RF | 802 | 18 | –19.680 | 0.000 | Yes |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tien Bui, D.; Shirzadi, A.; Chapi, K.; Shahabi, H.; Pradhan, B.; Pham, B.T.; Singh, V.P.; Chen, W.; Khosravi, K.; Bin Ahmad, B.; et al. A Hybrid Computational Intelligence Approach to Groundwater Spring Potential Mapping. Water 2019, 11, 2013. https://doi.org/10.3390/w11102013
Tien Bui D, Shirzadi A, Chapi K, Shahabi H, Pradhan B, Pham BT, Singh VP, Chen W, Khosravi K, Bin Ahmad B, et al. A Hybrid Computational Intelligence Approach to Groundwater Spring Potential Mapping. Water. 2019; 11(10):2013. https://doi.org/10.3390/w11102013
Chicago/Turabian StyleTien Bui, Dieu, Ataollah Shirzadi, Kamran Chapi, Himan Shahabi, Biswajeet Pradhan, Binh Thai Pham, Vijay P. Singh, Wei Chen, Khabat Khosravi, Baharin Bin Ahmad, and et al. 2019. "A Hybrid Computational Intelligence Approach to Groundwater Spring Potential Mapping" Water 11, no. 10: 2013. https://doi.org/10.3390/w11102013