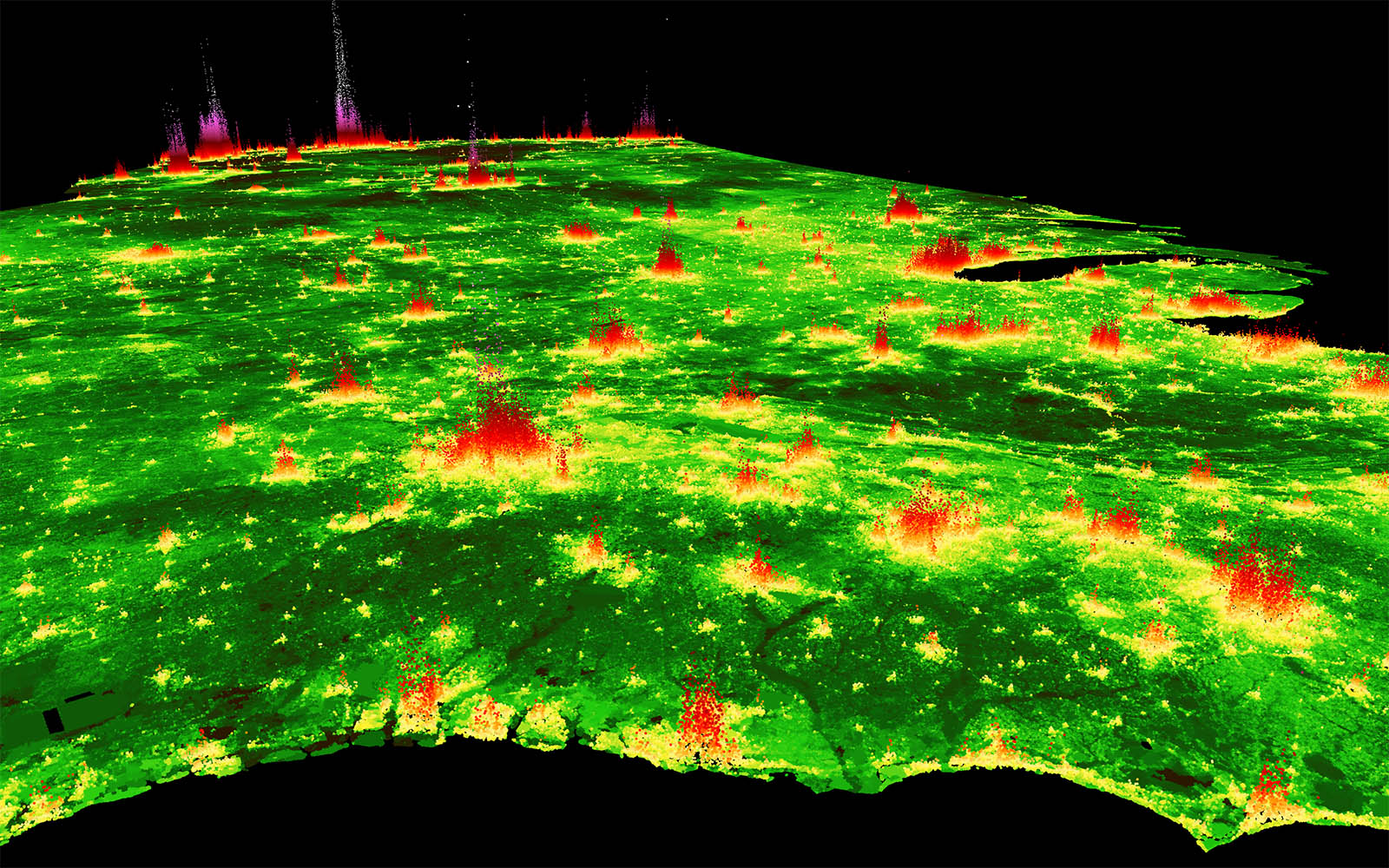
High-resolution maps of estimated fair market value of private properties in the contiguous United States.
We estimated U.S. land values at the property level from data on private transactions. As of Nov 9, 2020, these estimates were the best open predictor data for the actual cost of publicly-funded land acquisitions for conservation in the contiguous United States (Nolte 2020 PNAS).

Predictions are dependent on data quality and model assumptions. Ours capture some patterns relatively well (e.g., rural-urban gradients, valuable agricultural regions), but we don’t understand all of its potential biases. Scrutiny, feedback, and suggested improvements are welcome.
The National Science Foundation (Human-Environment and Geographical Sciences) is currently supporting us with a research grant (#2149243). We have until Jul 30, 2023, to understand our models better, improve training and validation data, and publish parcel-level predictions.
Early adopter program
Are you interested with working with parcel-level land value and conservation cost estimates for your policy decisions or policy-oriented research? Are you able to provide feedback on data interpretability and quality? We have begun to share preliminary datasets early with early adopters and will be discussing them during online workshops until June 2023. If you are interested in joining the group, please contact Christoph Nolte (chrnolte@bu.edu).
Maps & downloads
Data for: Nolte (2020) High-resolution land value maps reveal underestimation of conservation costs in the United States. Proceedings of the National Academy of Sciences of the U.S.A.
Download high-resolution figure (11MB) (these are predictions that consider development and building footprints).
{kind=link}
Download raster & validation data from Dryad. Includes rasterized maps of property value estimates at 480m resolution (unit: ln($/ha)), validation data, and comparison to Johnson et al. (2020, costs of floodplain acquisitions) and Lawler et al. (2020, costs of species habitat conservation). See published article for full documentation.
Finding local errors or implausible estimates? These are probably due to low local training data density. Feedback is welcome (chrnolte@bu.edu).
